python
注释
# 单行注释
‘’’
多行注释
‘’’
类型转换
在字符串,整数,浮点数之间相互转换。
int(x) 转整数
float(x) 转浮点数
str(x) 转字符串
type() 查类型
标识符
起名字,用于给变量、类、方法等命名
标识符中只允许英文,数字,中文,下划线,大小写敏感,不可使用关键字
运算符
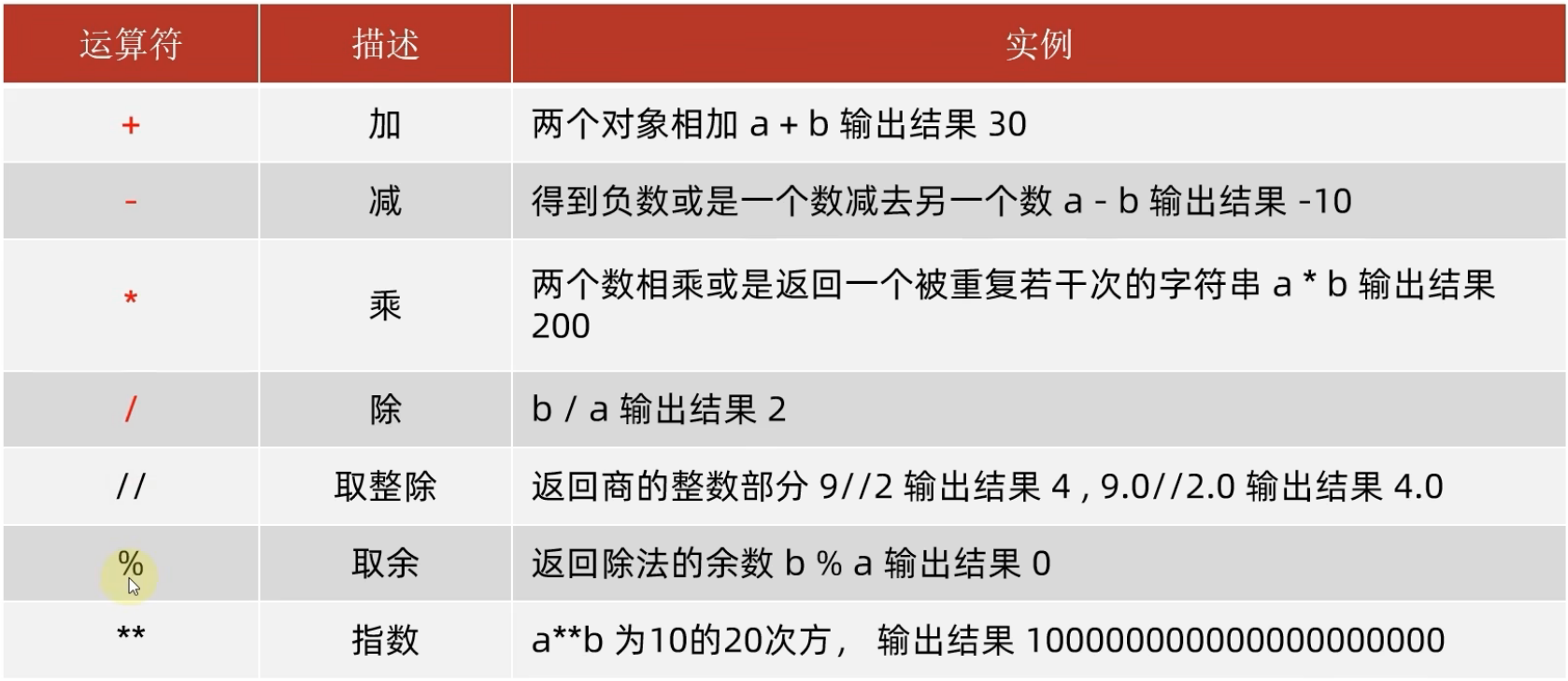
字符串
定义形式
1.单引号:name=’123’
2.双引号:name=”123”
3.三引号:name=”””123””” 使用变量接受三引号,里面的内容就变成了字符串
字符串的拼接
通过+来进行拼接 但不同类型的数据不能够通过这种方式拼接
例如,print(“xi”+”ao”) 输出xiao
字符串格式化
name=” %占位符” % 变量 可以将不同类型的数据拼接在一起,原理是将变量转换格式
占位符:
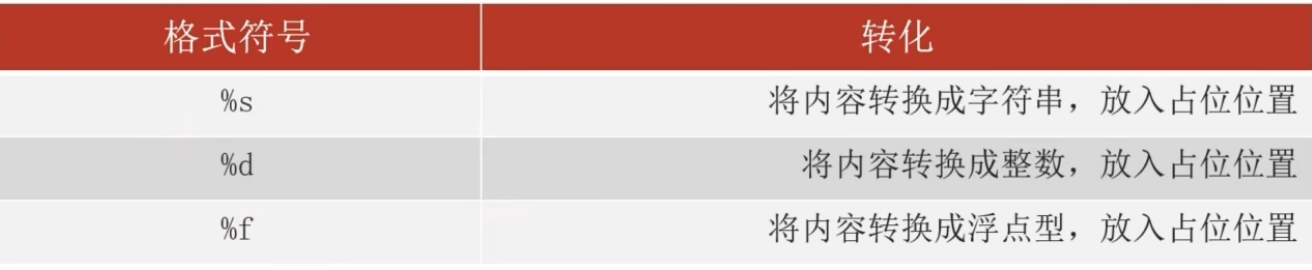
数字精度的控制
%5d 控制宽度,%.2f 保留两位小数,会四舍五入

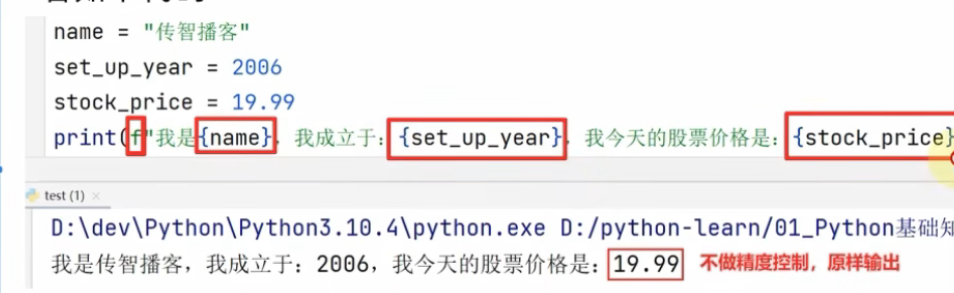
优雅的格式化方法
语法:f’内容{变量}’
特点:不限数据类型,不能控制精度
数据输入
使用input()语句来读取键盘输入的内容 输出的语句是字符串类型的,如有需要,可以进行数据类型转换
if语句
if 条件:
语句
(要进行缩进,if语句后面有冒号)
if 条件:
语句
else:
语句
if 条件1:
语句(条件1满足)
elif 条件2:
语句(条件2满足)
else :
语句(条件1,2都不满足)
如果else不写,效果等同于2个独立的if判断
判断是互斥且有序的,如果满足了第一个条件,那么后面的语句就不会再执行
嵌套
会的都会
python通过空格缩进来决定层数
循环
while循环 条件循环
while 条件:
语句
(同样需要缩进)
嵌套循环
注意条件的控制,避免无限循环
print(“hellow” ,end=” “) 使用end’输出不换行
for循环 遍历循环
for 临时变量 in 待处理数据集(序列):
循环满足条件时执行的代码
数据集包括字符串,列表,元组等
range语句
语法1:
range(num) 获取一个从0开始,到num结束的数字本身(不含num)
语法2:
range(num1,num2) 获取一个从num1开始,到num2结束的数字本身(不含num2)
语法3:
range(num1,num2,step) 获取一个从num1开始,到num2结束的,每次加step个步长值的数字本身(不含num2)
for循环中的临时变量,其作用域限定于:for循环内,如需访问变量,可以预先在循环外定义
continue和break
continue:
作用:中断本次循环,直接进入下一次循环
范围:continue作用范围作用于它所在的那一层循环中
break:
直接结束break所在的循环
在嵌套循环中,只能作用于所在的循环上,无法影响上一层循环
函数
定义:
def 函数名(传入参数):
函数体
return 返回值
变量=函数(参数)
函数定义时,使用的参数,称为形参
函数调用时,使用的参数,称为实参
如果函数没有返回值,会传出一个none(无返回值)
函数的说明文档
在函数内使用“”“注释”“”

函数变量的作用域
局部变量:定义在函数内部的变量,只能在函数体内部生效
全局变量:函数体内,外都能生效的变量
global关键字声明变量为全局变量
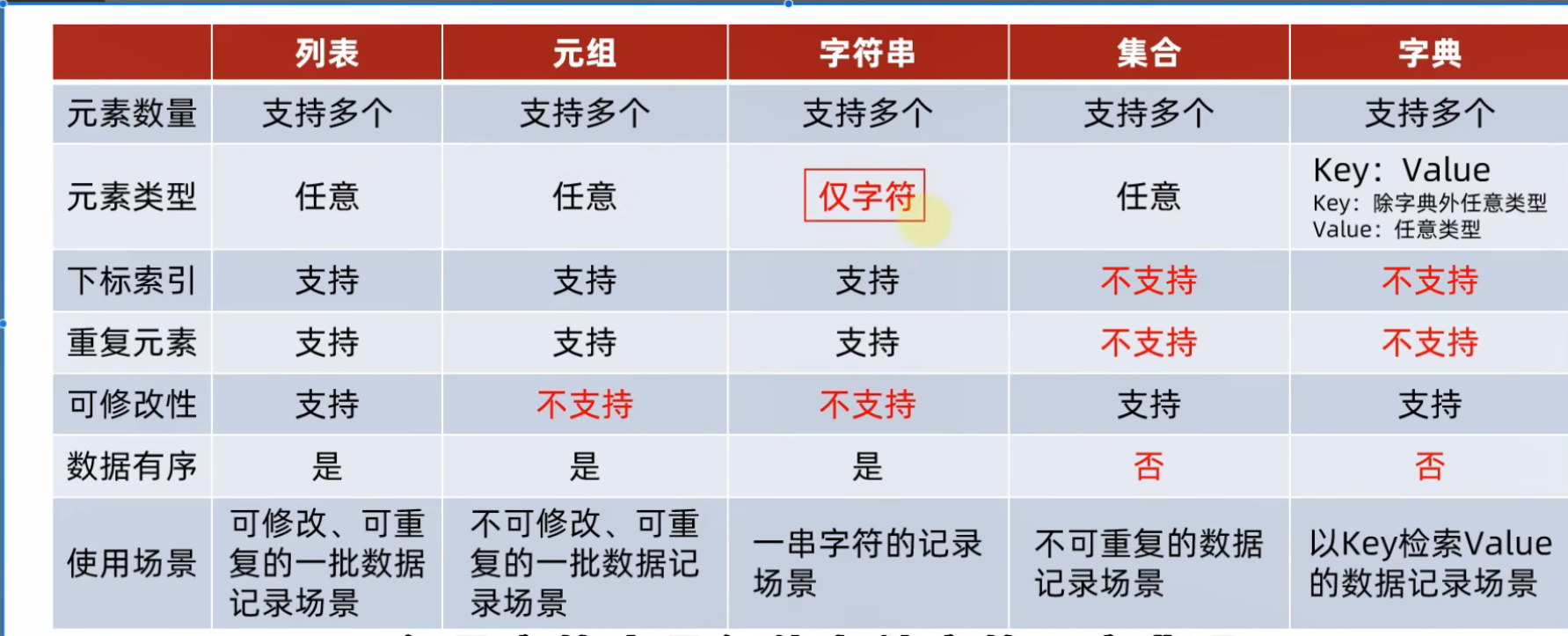
数据容器
定义:一种可以存储多个元素的python数据类
分类:list(列表),tuple(元组),str(字符串),set(集合),dict(字典)
list列表
语法:变量名称=[元素1,元素2,……]
定义空列表:a=[]
a=list()
嵌套:a=[a,[a,1,2],[a]]
列表下标索引从前往后依次为0,1,2,3,…
从后忘前依次为-1,-2,-3,…
列表的方法
查找某元素的下标
功能:查找指定元素的在列表中的下标,找不到返回valueerror
语法:列表.index(元素) 只会查出第一次出现的位置
修改特定位置的元素值
语法:列表[下标]=值
列表插入元素
语法:列表.insert(下标,元素)
列表元素的追加
语法1:列表.append(元素), 将指定元素追加到列表尾部
语法2:列表.extend(其它数据容器) ,将其它数据容器的内容取出,依次追加到列表尾部
列表元素的删除和清空
语法1:del 列表[下标]
语法2:列表.pop(下标)
语法3:列表.remove(元素) 删除某元素在列表中的第一个匹配值0
语法4:列表.clear() 清空列表内容
统计某元素在列表内的数量
语法:列表.count(元素)
统计列表中有多少元素
语法:len(列表)

列表的遍历
while循环
a=0
b=[1,2,3]
while a<len(b):
print(b[a])
a+=1
for循环
for 临时变量 in 数据容器:
print(临时变量)

tuple元组
定义:可以封装多个,不同类型的元素,但元组一旦定义完成,就不可修改
语法:
变量=(元素,元素,……)
定义空元组
变量=( )
变量=tuple()
定义单个元素为元组,要在元素后面加逗号,不然就变成了字符串
元组方法

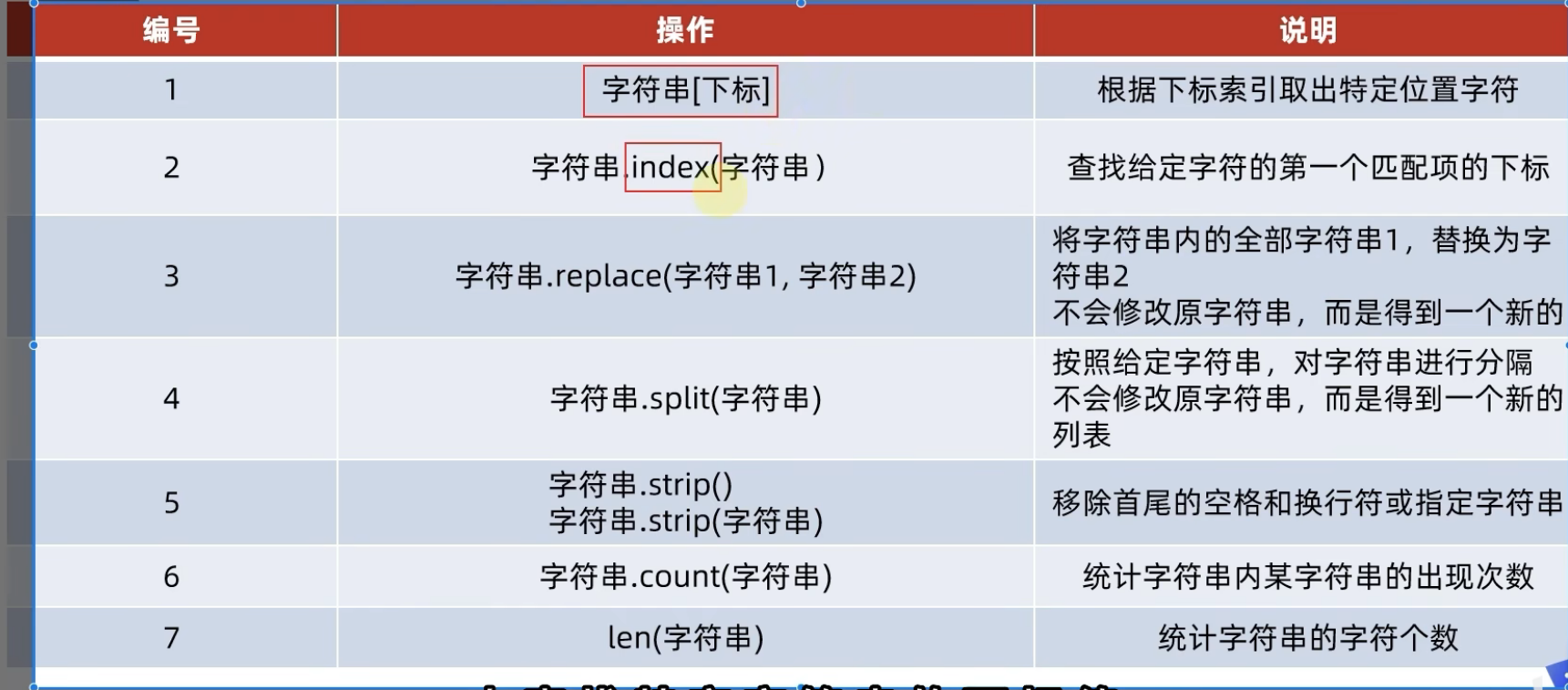
str字符串
方法
查找特定字符串的下标索引值
语法:字符串.index(字符串)
字符串的替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换成字符串2
(不是修改字符串本身,而是得到了一个新的字符串)
字符串的分割
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
字符串的规整操作(去前后格)
语法:字符串.strip()
字符串的规整操作(去前后指定字符串)
语法:字符串.strip(字符串)
统计字符串中某字符串的出现次数
语法:字符串.count(字符串)
统计长度
语法:len(字符串)
数据容器的切片
序列的切片,即:列表、元组、字符串,均支持切片
语法:序列[起始下标:结束下标:步长]

set集合
语法:变量名称={元素,元素,元素}
定义空集合:变量名称=set()
集合不支持下标索引访问,但允许修改
方法:
添加
语法:集合.add(元素)。将指定元素添加到集合内
结果:集合本身被修改,添加了新元素
移除元素
语法:集合.remove(元素)
从集合中随机取出元素
语法:集合.pop(),
功能:从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
清空集合
语法:集合.clear()
取出2个集合的差集
语法:集合1.difference(集合2)
功能:取出集合1和集合2的差集(集合1有的而集合2没有的)
结果:得到一个新集合,集合1,集合2不变
消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1中,删除和集合2相同的元素
结果:集合1被修改,集合2不变
2个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合,集合1,集合2不变
统计集合数量
语法:len(集合)

集合的遍历
用for循环
dict字典
字典的定义,使用{},但存储的元素是键值对
dict={key: value,key value,…}
定义空字典 dict={}
dict=dict()
(定义重复key时,后面的key会把前面的key覆盖掉,所以字典不允许重复)
字符数据的获取
语法:字典同集合一样,不可以使用下标索引,但可以通过key值来取得对应的value
st={key1:1,key2:2….}
print(st[key1])
字典的嵌套
字典里套层字典
{key:{key:value
key:value
}}
字典的常用操作
新增元素
语法:字典[key]=value,
结果:字典被修改,新增了元素
更新元素
语法:字典[key]=value,
结果:字典被修改,元素被更新
(字典key不可重复,所以对已存在的key执行上述操作,就是更新)
删除元素
语法:字典.pop(key)
结果:获得指定key的value,同时字典被修改,指定key的数据被删除
清空字典
语法:字典.clear()
结果:字典被清空
获取全部的key
语法:字典.keys()
结果:得到字典中全部key
遍历字典
方法1:通过获取到全都的key来完成遍历
for key in 字典.keys():
……
方法2:直接对字典进行for循环,每一次循环都是直接得到key
for key in 字典:
……
(不能使用while循环)
统计字典
语法:len(字典)

总结

数据容器的通用统计功能
len(容器) 统计元素个数
max(容器) 统计容器的最大元素
min(容器) 统计容器的最小元素
通用类型转换
list(容器)
str(容器)
tuple(容器)
set(容器)
通用排序功能
sort(容器1,[reverse=true])
功能:将定容器进行排序
函数进阶
函数的多返回值

函数的多种传参方式
位置参数:调用函数时根据函数定义的参数位置来传参
def add(a,b,c):
return a+b+c
sum=add(1,2,3)
关键字参数:函数调用时通过“键=值”形式传递参数
作用:可以让函数更加清晰可见,同时也消除了参数的顺序要求
def add(a,b,c):
return a+b+c
sum=add(a=1,b=2,c=3)
顺序可以颠倒,但如果有位置参数时,位置参数必须在关键字参数的前面
缺省参数

不定长传参
位置传递

关键字传递


函数作为参数传递
def test(add):
sum=add(1,2)
print(sum)
def add(a,b)
return a+b
函数add作为参数传入了test函数,这是一种计算逻辑的传递,而非数据的传递
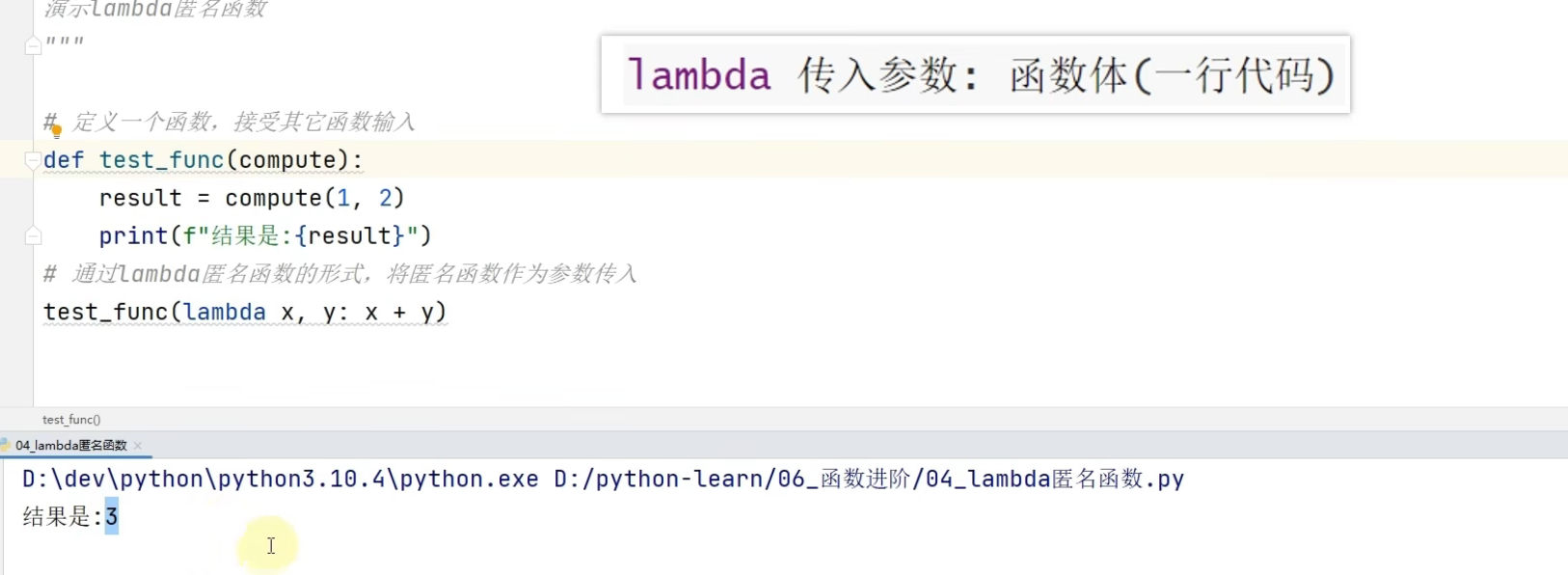
lambda匿名函数
def关键字定义带有名称的函数
lambda关键字,可以定义匿名函数(无名称)
有名称的函数。可以基于名称重复使用
无名称的,只可临时使用一次
语法:lambda 传入参数:函数体(一行代码)
lambda 是关键字,表示定义匿名函数
传入参数表示匿名函数的形式参数,如:x,y表示接收2个形式参数
函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
文件
文件的编码
编码就是一种规则集合,记录了内容和二进制间进行相互转换的逻辑。
编码有许多种,我们最常用的是utf-8编码
文件的读取
文件的打开
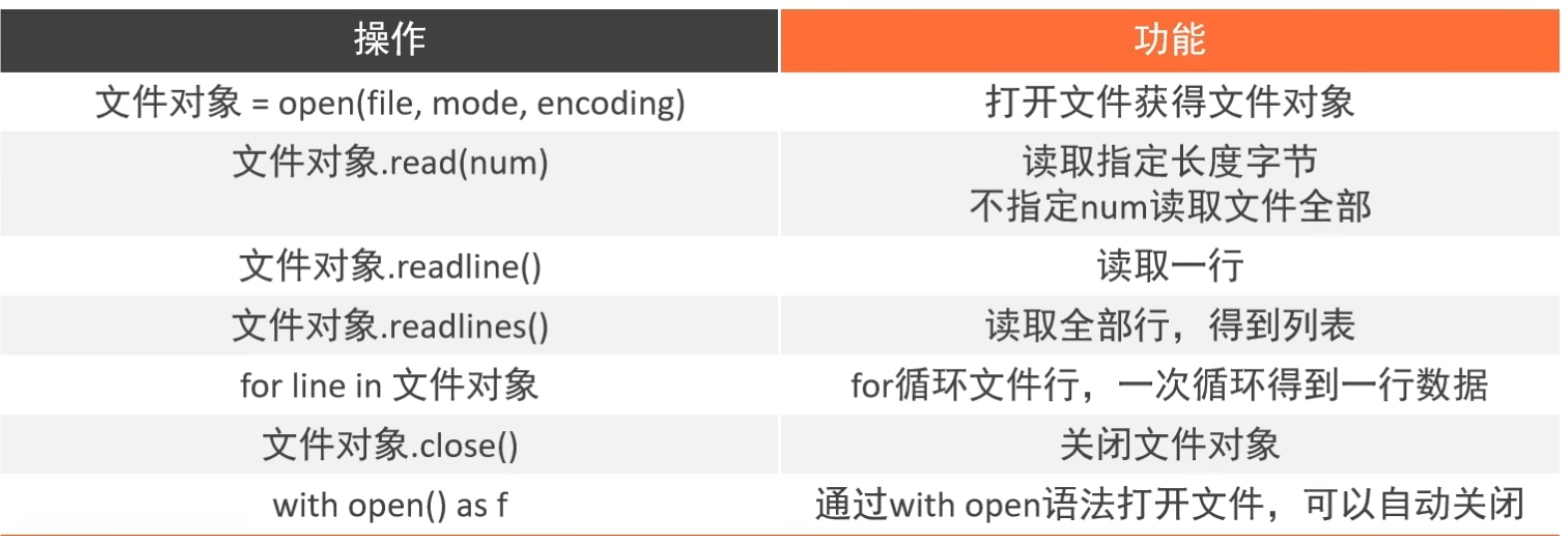
语法:open(name,mode,encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式(推荐使用utf-8)
file=open(‘python.txt’,’r’,encoding=’’ UTF-8”)
(encoding 的顺序不是第三位,所以不能用位置参数,用关键字参数直接指定)
mode常用的三种基础访问模式

读操作的相关方法
read()方法
语法:文件对象.read()
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中的全部数据
readlines()方法
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中的每一行数据表示一个元素

readline()方法:
一次读取一行内容

for循环读取文件
file=open(文件,’r’,encoding=’utf-8’)
for line in file:
print(f’{line}’)
每一个liine变量,就记录了文件的一行数据
文件的关闭
close()关闭文件对象
f=open(“文件”,”r”)
f.close()
如果不调用close,同时程序没有停止运行,那么这个文件将一直被python程序占用
with open语法
with open(“文件”,”r”) as f:
f.readlines()
通过在with open的语句块中对文件进行操作
可以在操作完成后自动关闭close文件
文件的写入
1.打开文件
f=open(“python.txt”,’w’)
2.文件写入
f.write(‘hellow world’)
3.内容刷新
f.flush()
注意:
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件
这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
当文件存在时,你文件写入时,会把原来文件中的东西覆盖掉
文件的追加

异常,模块和包
异常:当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”也就是我们常说的BUG
异常的处理(捕获)
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段
捕获常规异常
捕获全部的异常
语法:try:
可能发生错误的代码
except:
如果出现异常执行的代码

捕获指定异常
语法:
try:
except 异常名称 as a:
捕获多个异常
当捕获多个异常是,可以把要捕获的异常类型的名字,放到except后,并使用元组的方式进行书写
语法:try:
print(1/0)
except(NameError,ZeroDivisionError):
print()
异常else
else语句是没有出现异常的语句

异常finally

异常的传递性

python模块
模块的导入
模块是个python文件,里面有类、函数、变量,我们可以导入模块去使用
语法:
[from 模块名] import [模块 | 类 | 变量 | 函数 | *][as 别名]
常用组合:
import 模块名
from 模块名 import 类、变量、方法
import 模块名 as 别名
from 模块名 import 功能名 as 别名