正则表达式
限定符
?
表示?前面的字符出现一次或0次,意思是?前的字符可有可无
例如:used? 表示d可以出现0次或1次
*
可以匹配0个或多个字符
例如:ab*c 表示b可以出现0次或多次
+
可以匹配出现一次或一次以上的字符
例如:ab+c 表示b可以出现1次或1次以上
{}
{a} 可以进行精确的匹配a次
{a,b}可以匹配字符的次数为a到b次
例如:指定b出现的次数为6 可以写 ab{6}c
指定b出现的次数为2到6次 可以写ab{2,6}c
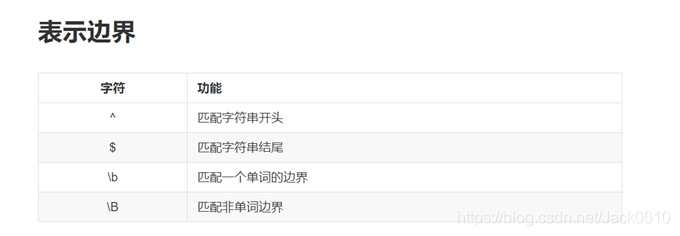
匹配多个字符
()
例如(ab)+,表示ab出现1次或1次以上
或运算符
|
例如a-(cat|dog) , 会匹配到 a-cat和a-dog
如果去掉(), 就会变成a-cat|dog,则会匹配到a-cat和dog
所以括号必不可少
字符类
例如
[abc]+ 方括号里的内容代表要求匹配的字符只能取自它们
可以在方括号里指定字符的范围
[a-z]代表所有的小写英文字符
[a-zA-z]代表所有的英文字符
[0-9]代表所有的数字
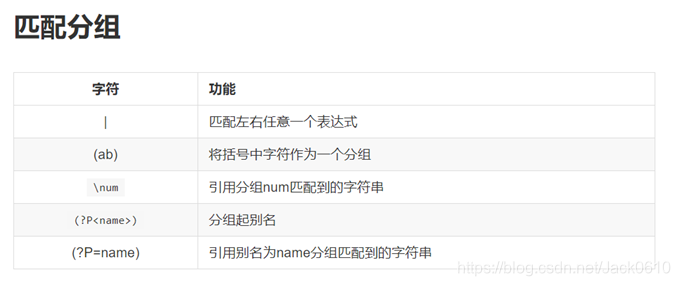
^
如果在方括号的前面写上一个^,则代表要求匹配出了尖号后面列出的以外的字符
例如:[^0-9]代表所有的非数字字符(包括换行符)
元字符
\d
代表数字字符
\w
代表单词字符,也就是所有的英文字符,数字和下划线
\s
代表空白符,包含(tab字符和换行符)
\D
代表非数字字符
\W
代表非单词字符
\S
代表非空白字符
.
代表所有字符,但不包括换行符 例如:.*
^
会去匹配行首
例如^a会去匹配行首的a
$
会去匹配行尾
例如a$会去匹配行尾的a
贪婪与懒惰匹配
?
将正则表达式中的贪婪匹配转换成正则匹配
例如
想要匹配 This中的html标签,我们会想到使用<.+>,
但这会匹配整个字符串,原因是因为.+会匹配尽可能多的字符,
因此,使用<.+?>就可以正确匹配了
在表达式末尾加入\b表达单词字符的边界

模式修正符

举例说明正则符号的定义方式:
1 | 例子 说明 |
表示边界
匹配分组