基本介绍
Rust 是由 Mozilla 团队于 2010 年推出的系统级编程语言,专注于 安全性、性能 和 并发性。它通过独特的编译时检查机制(如所有权系统),在无需垃圾回收(GC)的前提下保障内存安全,同时性能媲美 C/C++,被 Stack Overflow 评为最受开发者喜爱的语言之一(2016-2023 连续多年)。
我们来通过一段代码来简单浏览一下Rust语法
1 | // Rust 程序入口函数,跟其它语言一样,都是 main,该函数目前无返回值 |
注意:
- 字符串使用双引号
""而不是单引号'',Rust 中单引号是留给单个字符类型(char)使用的 - Rust 使用
{}来作为格式化输出占位符,其它语言可能使用的是%s,%d,%p等,由于println!会自动推导出具体的类型,因此无需手动指定
变量绑定与解构
变量命名
rust和其它语言一样,都需要遵循命名规范
下面是一些例子:
| 类型 | 命名风格 | 示例 |
|---|---|---|
| 变量、函数、模块 | 蛇形命名法(snake_case) | calculate_length, user_name |
| 结构体、枚举、特性 | 大驼峰式(PascalCase) | String, HttpRequest, FromStr |
| 常量和静态变量 | 全大写蛇形(SCREAMING_SNAKE_CASE) | MAX_CONNECTIONS, DEFAULT_PORT |
| 生命周期参数 | 短小写字母 + 单引号 | 'a, 'ctx, 'static |
| 泛型类型参数 | 简明的大驼峰式或单字母 | T, K, V, Context |
变量绑定
在其他的语言里,我们使用var a="hello world"的方式给a复制,也就是把等式右边的字符串赋给了变量a,而在rust中,我们使用let a="hello world",我们在rust中称这个过程为变量绑定
为什么使用变量绑定忙着哩设计了Rust最核心的原则——所有权,简单来讲,任何内存对象都是有主人的,而且一般情况完全属于它的主人,绑定就是把这个对象绑定给一个变量,让这个变量成为它的主人(在这种情况下,该对象之前的主人就会丧失对该对象的所有权)
绑定就意味着不可变了吗?
变量的可变性
Rust一般情况下是不可变的,但如果实在想变,可以使用**mut**关键字来使变量可变
如果我们不使用mut,那么变量一旦绑定一个数,就不能再绑定另一个数了
例如我们不使用mut ,在新建的 variables 目录下,编辑 src/main.rs ,改为下面代码:
1 | fn main() { |
保存文件,再用cargo run运行
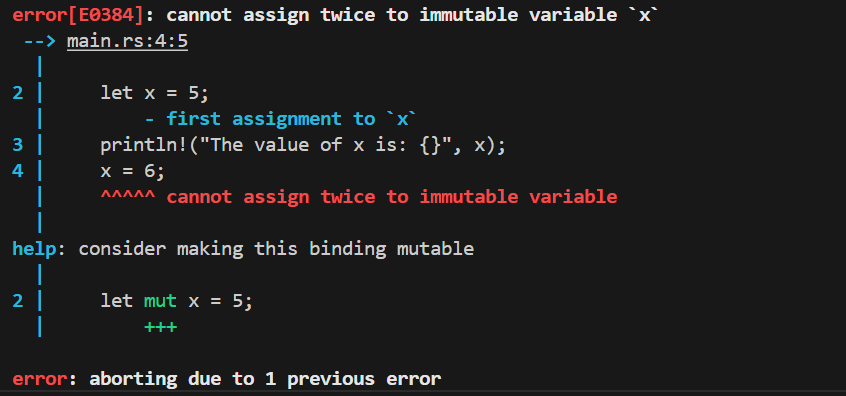
报了一个错,具体的错误原因是 cannot assign twice to immutable variable x(无法对不可变的变量进行重复赋值),因为我们想为不可变的 x 变量再次赋值。
这种错误是为了避免无法预期的错误发生在我们的变量上:一个变量往往被多处代码所使用,其中一部分代码假定该变量的值永远不会改变,而另外一部分代码却无情的改变了这个值,在实际开发过程中,这个错误是很难被发现的,特别是在多线程编程中。
如果我们使用mut,代码就能成功执行
1 | fn main() { |

所以选择可变还是不可变,取决于你的使用场景,例如不可变可以带来安全性,但是丧失了灵活性和性能(如果你要改变,就要重新创建一个新的变量,这里涉及到内存对象的再分配)。而可变变量最大的好处就是使用上的灵活性和性能上的提升。
使用下划线开头忽略未使用的变量
如果你创建了一个变量却不在任何地方使用它,Rust就会给出一个警告,因为这可能会是个 BUG,如果不希望rust给出警告,就可以在rust前面加一个下划线来避免它
1 | fn main(){ |
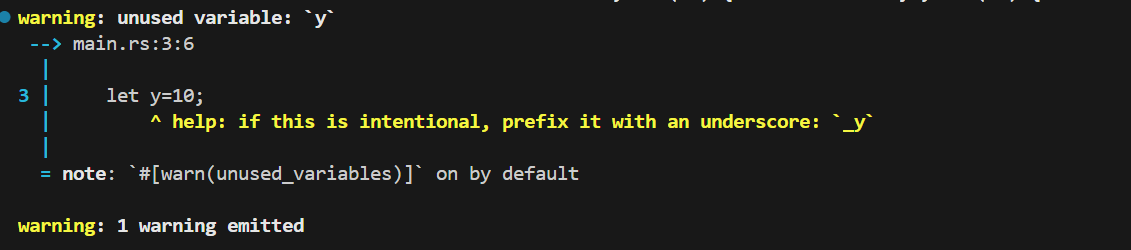
可以看到,两个变量都是只有声明,没有使用,但是编译器却独独给出了 y 未被使用的警告,充分说明了 _ 变量名前缀在这里发挥的作用。并且rust给出了修复的建议
变量解构
let 表达式不仅仅用于变量的绑定,而且还能进行复杂变量的解构:从一个相对复杂的变量里,匹配出该变量的一部分.
1 | fn main() { |
解构式赋值
解构式赋值是指将一个复合数据类型(如元组、数组、结构体等)的内部值提取并赋值给多个变量的操作。在 Rust 中,解构赋值通常用于将一个复杂的数据结构的各个部分提取到单独的变量中。
解构式赋值在 Rust 中并不直接使用“赋值”的形式(如传统编程语言中的解构赋值),而是通过模式匹配来实现的。在 Rust 中,这种解构通常是通过 let 语句和匹配模式(如元组模式、数组模式、结构体模式等)来完成的。
在 Rust 1.59 版本后,我们可以在赋值语句的左式中使用元组、切片和结构体模式了。
1 | struct Struct { |
这种使用方式跟之前的 let 保持了一致性,但是 let 会重新绑定,而这里仅仅是对之前绑定的变量进行再赋值。
需要注意的是,使用 += 的赋值语句还不支持解构式赋值。
变量和常量之间的差异
变量的值不能更改可能让你想起其他另一个很多语言都有的编程概念:常量(constant)。与不可变变量一样,常量也是绑定到一个常量名且不允许更改的值,但是常量和变量之间存在一些差异:
- 常量不允许使用
mut。常量不仅仅默认不可变,而且自始至终不可变,因为常量在编译完成后,已经确定它的值。 - 常量使用
const关键字而不是let关键字来声明,并且值的类型必须标注。
下面是一个常量声明的例子,其常量名为 MAX_POINTS,值设置为 100,000。(Rust 常量的命名约定是全部字母都使用大写,并使用下划线分隔单词,另外对数字字面量可插入下划线以提高可读性):
1 | const MAX_POINTS: u32 = 100_000; |
常量可以在任意作用域内声明,包括全局作用域,在声明的作用域内,常量在程序运行的整个过程中都有效。对于需要在多处代码共享一个不可变的值时非常有用,例如游戏中允许玩家赚取的最大点数或光速。
在实际使用中,最好将程序中用到的硬编码值都声明为常量,对于代码后续的维护有莫大的帮助。如果将来需要更改硬编码的值,你也只需要在代码中更改一处即可。
变量的遮蔽
rust允许声明相同的变量名,但后面的变量名会遮蔽掉前面的变量名
1 | fn main() { |
输出

这个程序首先将数值 5 绑定到 x,然后通过重复使用 let x = 来遮蔽之前的 x,并取原来的值加上 1,所以 x 的值变成了 6。第三个 let 语句同样遮蔽前面的 x,取之前的值并乘上 2,得到的 x 最终值为 12。
这和 mut 变量的使用是不同的,第二个 let 生成了完全不同的新变量,两个变量只是恰好拥有同样的名称,涉及一次内存对象的再分配 ,而 mut 声明的变量,可以修改同一个内存地址上的值,并不会发生内存对象的再分配,性能要更好。
基本类型
Rust 每个值都有其确切的数据类型,总的来说可以分为两类:基本类型和复合类型。 基本类型意味着它们往往是一个最小化原子类型,无法解构为其它类型(一般意义上来说),由以下组成:
- 数值类型:有符号整数 (
i8,i16,i32,i64,isize)、 无符号整数 (u8,u16,u32,u64,usize) 、浮点数 (f32,f64)、以及有理数、复数 - 字符串:字符串字面量和字符串切片
&str - 布尔类型:
true和false - 字符类型:表示单个 Unicode 字符,存储为 4 个字节
- 单元类型:即
(),其唯一的值也是()
数值类型
整数类型
整数是没有小数部分的数字,之前使用过的i32类型,表示有符号的32为整数(i是英文单词integer的首字母,与之相反的是u,代表无符号的unsigned类型),下表显示了Rust中的内置函数整数类型:
| 长度 | 有符号类型 | 无符号类型 |
|---|---|---|
| 8 位 | i8 |
u8 |
| 16 位 | i16 |
u16 |
| 32 位 | i32 |
u32 |
| 64 位 | i64 |
u64 |
| 128 位 | i128 |
u128 |
| 视架构而定 | isize |
usize |
类型定义的形式统一为:有无符号 + 类型大小(位数)。无符号数表示数字只能取正数和 0,而有符号则表示数字可以取正数、负数还有 0。就像在纸上写数字一样:当要强调符号时,数字前面可以带上正号或负号;然而,当很明显确定数字为正数时,就不需要加上正号了。有符号数字以补码形式存储。
每个有符号类型规定的数字范围是 -(2n - 1) ~ 2n - 1 - 1,其中 n 是该定义形式的位长度。因此 i8 可存储数字范围是 -(27) ~ 27 - 1,即 -128 ~ 127。无符号类型可以存储的数字范围是 0 ~ 2n - 1,所以 u8 能够存储的数字为 0 ~ 28 - 1,即 0 ~ 255。
此外,isize 和 usize 类型取决于程序运行的计算机 CPU 类型: 若 CPU 是 32 位的,则这两个类型是 32 位的,同理,若 CPU 是 64 位,那么它们则是 64 位。
整型字面量可以用下表的形式书写:
| 数字字面量 | 示例 |
|---|---|
| 十进制 | 98_222 |
| 十六进制 | 0xff |
| 八进制 | 0o77 |
| 二进制 | 0b1111_0000 |
字节 (仅限于 u8) |
b'A' |
整型溢出
假设我们有个u8类型的数,它可以存放0到255的数,如果我们修改为256或更大,就会发生整型溢出,关于这一行为 Rust 有一些有趣的规则:当在 debug 模式编译时,Rust 会检查整型溢出,若存在这些问题,则使程序在编译时 panic(崩溃,Rust 使用这个术语来表明程序因错误而退出)。
在当使用 --release 参数进行 release 模式构建时,Rust 不检测溢出。相反,当检测到整型溢出时,Rust 会按照补码循环溢出(two’s complement wrapping)的规则处理。简而言之,大于该类型最大值的数值会被补码转换成该类型能够支持的对应数字的最小值。比如在 u8 的情况下,256 变成 0,257 变成 1,依此类推。程序不会 panic,但是该变量的值可能不是你期望的值。依赖这种默认行为的代码都应该被认为是错误的代码。
要显式处理可能的溢出,可以使用标准库针对原始数字类型提供的这些方法:
- 使用
wrapping_*方法在所有模式下都按照补码循环溢出规则处理,例如wrapping_add - 如果使用
checked_*方法时发生溢出,则返回None值 - 使用
overflowing_*方法返回该值和一个指示是否存在溢出的布尔值 - 使用
saturating_*方法,可以限定计算后的结果不超过目标类型的最大值或低于最小值,例如:
1 | //101没有超过u8的最大值,过可以返回101 |
下面是一个演示wrapping_*方法的示例
1 | fn main() { |
输出是19,相当于是275mod256=19
浮点类型
浮点类型数字是带有小数点的数字,在rust中浮点类型也有两种基本类型:f32和f64,分别为32位和64位大小。默认浮点类型是f64,在线代的CPU中它的速度与f32几乎相同,但精度更高
1 | fn main() { |
f32 类型是单精度浮点型,f64 为双精度。
注意:1.浮点数往往是你想要数字的近似表达
2.浮点数在某些特性上是反直觉的
所以有些浮点数虽然看上去相等,但由于精度问题,并不相等
NaN
对于数学上未定义的结果,例如对负数取平方根 -42.1.sqrt() ,会产生一个特殊的结果:Rust 的浮点数类型使用 NaN (not a number) 来处理这些情况。
**所有跟 NaN 交互的操作,都会返回一个 NaN**,而且 NaN 不能用来比较,下面的代码会崩溃:
1 | fn main() { |
出于防御性编程的考虑,可以使用 is_nan() 等方法,可以用来判断一个数值是否是 NaN :
1 | fn main() { |
所以NaN的用处大概是用来抛出计算过程中的异常的
数字运算
1 | fn main() { |
这些语句中的每个表达式都使用了数学运算符,并且计算结果绑定到一个变量上,附录 B 中给出了 Rust 提供的所有运算符的列表。
再来看一个综合性的示例:
1 | fn main() { |
位运算
Rust 的位运算基本上和其他语言一样
| 运算符 | 说明 |
|---|---|
| & 位与 | 相同位置均为1时则为1,否则为0 |
| | 位或 | 相同位置只要有1时则为1,否则为0 |
| ^ 异或 | 相同位置不相同则为1,相同则为0 |
| ! 位非 | 把位中的0和1相互取反,即0置为1,1置为0 |
| << 左移 | 所有位向左移动指定位数,右位补0 |
| >> 右移 | 所有位向右移动指定位数,带符号移动(正数补0,负数补1) |
序列
用..来表示范围,例如 1..5,生成从 1 到 4 的连续数字,不包含 5 ;1..=5,生成从 1 到 5 的连续数字,包含 5,它的用途很简单,常常用于循环中:
1 | for i in 1..=5 { |
最终程序输出1到5
注意:序列只允许用于数字或字符类型,原因是:它们可以连续,同时编译器在编译期可以检查该序列是否为空,字符和数字值是 Rust 中仅有的可以用于判断是否为空的类型。
使用 As 完成类型转换
Rust 中可以使用 As 来完成一个类型到另一个类型的转换,其最常用于将原始类型转换为其他原始类型,但是它也可以完成诸如将指针转换为地址、地址转换为指针以及将指针转换为其他指针等功能。你可以在这里了解更多相关的知识。
1 | fn main() { |
有理数和复数
Rust 的标准库相比其它语言,准入门槛较高,因此有理数和复数并未包含在标准库中:
- 有理数和复数
- 任意大小的整数和任意精度的浮点数
- 固定精度的十进制小数,常用于货币相关的场景
好在社区已经开发出高质量的 Rust 数值库:num。
按照以下步骤来引入 num 库:
- 创建新工程
cargo new complex-num && cd complex-num - 在
Cargo.toml中的[dependencies]下添加一行num = "0.4.0" - 将
src/main.rs文件中的main函数替换为下面的代码 - 运行
cargo run
1 | use num::complex::Complex; |
字符、布尔、单元类型
字符类型(char)
在rust中,不仅仅是ASCII,所有的Unicode、単个中文,日文、韩文、emoji 表情符号等等,都是合法的字符类型,占4个字节
1 | fn main() { |
布尔(bool)
拥有true和false,占1个字节
1 | fn main() { |
单元类型
单元类型就是 ()
语句及表达式
Rust 的函数体是由一系列语句组成,最后由一个表达式来返回值,例如:
1 | fn add_with_extra(x: i32, y: i32) -> i32 { |
语句会执行一些操作但是不会返回一个值,而表达式会在求值后返回一个值,因此在上述函数体的三行代码中,前两行是语句,最后一行是表达式。
对于 Rust 语言而言,这种基于语句(statement)和表达式(expression)的方式是非常重要的,你需要能明确的区分这两个概念,但是对于很多其它语言而言,这两个往往无需区分。基于表达式是函数式语言的重要特征,表达式总要返回值。
语句
1 | let a = 8; |
以上都是语句,它们完成一个具体的操作,但是并没有返回值,因此是语句
由于let是语句,那当然不能把一个语句赋给其他值
1 | let b = (let a = 8); |
上述操作会报错
表达式
表达式会进行求职,然后返回一个值,例如5+6在求值后会返回11,因此它是一个表达式
调用一个函数是表达式,因为会返回一个值,调用宏也是表达式,用花括号包裹最终返回一个值的语句块也是表达式,总之,能返回值,它就是表达式:
1 | fn main() { |
上面使用一个语句块表达式将值赋给 y 变量,语句块长这样:
1 | { |
注意:表达式不能包含分号。这一点非常重要,一旦你在表达式后加上分号,它就会变成一条语句,再也不会返回一个值
函数
1 | fn add(i: i32, j: i32) -> i32 { |
声明函数的关键字 fn,函数名 add(),参数 i 和 j,参数类型和返回值类型都是 i32
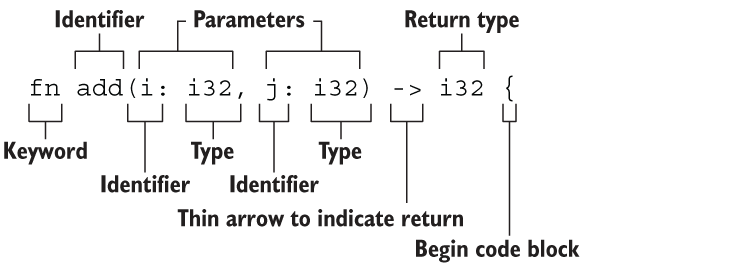
函数要点
- 函数名和变量名使用蛇形命名法(snake case),例如
fn add_two() -> {} - 函数的位置可以随便放,Rust 不关心我们在哪里定义了函数,只要有定义即可
- 每个函数参数都需要标注具体类型
1 | fn main() { |
x:i32的i32是必要的,去掉的话会报错
函数返回
在rust中,函数就是表达式,因此我们可以把函数的返回值直接给调用者。
函数的返回值就是函数体最后一条表达式的返回值,当然我们也可以使用 return 提前返回,下面的函数使用最后一条表达式来返回一个值:
1 | fn plus_five(x:i32) -> i32 { |
x + 5 是一条表达式,求值后,返回一个值,因为它是函数的最后一行,因此该表达式的值也是函数的返回值。
再来看两个重点:
let x = plus_five(5),说明我们用一个函数的返回值来初始化x变量,因此侧面说明了在 Rust 中函数也是表达式,这种写法等同于let x = 5 + 5;x + 5没有分号,因为它是一条表达式,所以函数最终返回的结果是x+5的结果
再来看一段代码,同时使用 return 和表达式作为返回值:
1 | fn plus_or_minus(x:i32) -> i32 { |
plus_or_minus 函数根据传入 x 的大小来决定是做加法还是减法,若 x > 5 则通过 return 提前返回 x - 5 的值,否则返回 x + 5 的值。
Rust 中的特殊返回类型
无返回值()
对于 Rust 新手来说,有些返回类型很难理解,而且如果你想通过百度或者谷歌去搜索,都不好查询,因为这些符号太常见了,根本难以精确搜索到。
例如单元类型 (),是一个零长度的元组。它没啥作用,但是可以用来表达一个函数没有返回值:
- 函数没有返回值,那么返回一个
() - 通过
;结尾的语句返回一个()
例如下面的 report 函数会隐式返回一个 ():
1 | use std::fmt::Debug; |
与上面的函数返回值相同,但是下面的函数显式的返回了 ():
1 | fn clear(text: &mut String) -> () { |
在实际编程中,你会经常在错误提示中看到该 () 的身影出没,假如你的函数需要返回一个 u32 值,但是如果你不幸的以 表达式; 的语句形式作为函数的最后一行代码,就会报错:
1 | fn add(x:u32,y:u32) -> u32 { |
错误如下:
1 | error[E0308]: mismatched types // 类型不匹配 |
注意:只有表达式能返回值,而 ; 结尾的是语句,在 Rust 中,一定要严格区分表达式和语句的区别,这个在其它语言中往往是被忽视的点。
永不返回的发散函数 !
当用 ! 作函数返回类型的时候,表示该函数永不返回( diverge function ),特别的,这种语法往往用做会导致程序崩溃的函数:
1 | fn dead_end() -> ! { |
下面的函数创建了一个无限循环,该循环永不跳出,因此函数也永不返回:
1 | fn forever() -> ! { |
所有权和借用
所有权
所有的程序都必须和计算机内存打交道,如何从内存中申请空间来存放程序的运行内容,如何在不需要的时候释放这些空间,成了重中之重,也是所有编程语言设计的难点之一。在计算机语言不断演变过程中,出现了三种流派:
- **垃圾回收机制(GC)**,在程序运行时不断寻找不再使用的内存,典型代表:Java、Go
- 手动管理内存的分配和释放, 在程序中,通过函数调用的方式来申请和释放内存,典型代表:C++
- 通过所有权来管理内存,编译器在编译时会根据一系列规则进行检查
其中 Rust 选择了第三种,最妙的是,这种检查只发生在编译期,因此对于程序运行期,不会有任何上的性能损失
栈和堆
栈和堆是编程语言最核心的数据结构,在rust中,值是位于栈还是堆上非常重要,这会影响程序的行为和性能
注意:栈和堆的核心目标就是为程序在运行时提供可供使用的内存空间
栈
栈按照顺序存储值并以相反顺序取出值,这中操作方式也被称作后进先出。
增加数据叫做进栈,减少数据叫做出栈
但是,栈中所有的数据都必须占用已知固定大小的内存空间,假设数据大小未知,那么在取出数据时,你讲无法取到你想要的数据
堆
与栈不同的是,当我们遇见大小未知或者可能变化的数据,我们就需要将其存储在堆上
当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在对的没出找到一块足够大的空位,把它标记为已使用,不返回一个表示该位置地址的指针,该过程被称为在堆上分配内存
接着,该指针会被推入栈中,因为指针大小固定,在后续使用过程中,将通过栈中的指针,来获取数据在堆上的时机内存位置, 进而访问该数据
由上可知,堆是一种缺乏组织的数据结构
性能区别
在栈上分配内存比在堆上分配内存要快,因为入栈是操作系统无需调用函数来分配现代科技,只需要将新数据放入栈顶即可。相比之下,在堆上分配内存则需要更多的工作,这是因为操作系统必须首先找到一块足够存放数据的内存空间,接着做一些记录为下一次分配空间做准备,如果当前进程分配的内存页不足时,还需要进行系统调用来申请更多内存。 因此,处理器在栈上分配数据会比在堆上分配数据更加高效。
所有权和堆栈
当你的代码调用一个函数时,传递给函数的参数(包括可能指向堆上数据的指针和函数的局部变量)依次被压入栈中,当函数调用结束时,这些值将被从栈中按照相反的顺序依次移除。
因为堆上的数据缺乏组织,因此跟踪这些数据何时分配和释放是非常重要的,否则堆上的数据将产生内存泄漏 —— 这些数据将永远无法被回收。这就是 Rust 所有权系统为我们提供的强大保障。
对于其他很多编程语言,你确实无需理解堆栈的原理,但是在 Rust 中,明白堆栈的原理,对于我们理解所有权的工作原理会有很大的帮助。
所有权原则
注意几点:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
变量作用域
作用域是一个变量在程序中有效的范围,假如有这样一个 变量:
1 | let s = "hello"; |
变量 s 绑定到了一个字符串字面值,该字符串字面值是硬编码到程序代码中的。s 变量从声明的点开始直到当前作用域的结束都是有效的:
1 | { // s 在这里无效,它尚未声明 |
简而言之,s 从创建开始就有效,然后有效期持续到它离开作用域为止,可以看出,就作用域来说,Rust 语言跟其他编程语言没有区别。
变量绑定背后的数据交互
转移所有权
先来看一段代码
1 | let x = 5; |
这段代码并没有发生所有权的转移,原因很简单: 代码首先将 5 绑定到变量 x,接着拷贝 x 的值赋给 y,最终 x 和 y 都等于 5,因为整数是 Rust 基本数据类型,是固定大小的简单值,因此这两个值都是通过自动拷贝的方式来赋值的,都被存在栈中,完全无需在堆上分配内存。
整个过程中的赋值都是通过值拷贝的方式完成(发生在栈中),因此并不需要所有权转移。
我们在来看下面代码:
1 | let s1=String::from("hello"); |
对于基本类型(存储在栈上),Rust 会自动拷贝,但是 String 不是基本类型,而且是存储在堆上的,因此不能自动拷贝。
String类型是一个字符串类型,由存储在栈中的堆指针、字符串长度、字符串容器组成,其中堆指针是最重要的,它指向了真实存储字符串内容的堆指针
关于上面let s2=s1,分成两种方式讨论
- 拷贝
String和存储在堆上的字节数组 如果该语句是拷贝所有数据(深拷贝),那么无论是String本身还是底层的堆上数据,都会被全部拷贝,这对于性能而言会造成非常大的影响 - 只拷贝
String本身 这样的拷贝非常快,因为在 64 位机器上就拷贝了8字节的指针、8字节的长度、8字节的容量,总计 24 字节,但是带来了新的问题,还记得我们之前提到的所有权规则吧?其中有一条就是:一个值只允许有一个所有者,而现在这个值(堆上的真实字符串数据)有了两个所有者:s1和s2。
好吧,就假定一个值可以拥有两个所有者,会发生什么呢?
当变量离开作用域后,Rust 会自动调用 drop 函数并清理变量的堆内存。不过由于两个 String 变量指向了同一位置。这就有了一个问题:当 s1 和 s2 离开作用域,它们都会尝试释放相同的内存。这是一个叫做 二次释放(double free) 的错误,也是之前提到过的内存安全性 BUG 之一。两次释放(相同)内存会导致内存污染,它可能会导致潜在的安全漏洞。
因此,Rust 这样解决问题:当 s1 被赋予 s2 后,Rust 认为 s1 不再有效,因此也无需在 s1 离开作用域后 drop 任何东西,这就是把所有权从 s1 转移给了 s2,s1 在被赋予 s2 后就马上失效了。
所以在上面代码中,当s1的所有权转移到了s2之后,s1就没有用了
克隆(深拷贝)
首先,Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何自动的复制都不是深拷贝,可以被认为对运行时性能影响较小。
如果我们实在想要胜读复制String堆上的数据,可以使用clone方法
1 | let s1 = String::from("hello"); |
能正常运行,没报错
拷贝(浅拷贝)
浅拷贝只发生在栈上,因此性能很高,在日常编程中,浅拷贝无处不在。
再回到之前看过的例子:
1 | let x = 5; |
但这段代码似乎与我们刚刚学到的内容相矛盾:没有调用 clone,不过依然实现了类似深拷贝的效果 —— 没有报所有权的错误。
因为任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的。如下是一些 Copy 的类型:
- 所有整数类型,比如
u32 - 布尔类型,
bool,它的值是true和false - 所有浮点数类型,比如
f64 - 字符类型,
char - 元组,当且仅当其包含的类型也都是
Copy的时候。比如,(i32, i32)是Copy的,但(i32, String)就不是 - 不可变引用
&T,例如转移所有权中的最后一个例子,但是注意:可变引用&mut T是不可以 Copy的
引用与借用
如果仅仅支持通过转移所有权的方式获取一个值,那会让程序变得复杂。因此,Rust通过借用来获取一个值,获取变量的引用,称之为借用
借用分为两种类型:
- 不可变引用:允许多个借用者同时读取该值,但不允许修改。
- 可变引用:只允许一个借用者修改该值,但在借用期间不能有其他借用者。
引用和解引用
常规引用时一个指针类型,指向了对象存储的内存地址。在下面代码中,我们创建了一个i32的值引用y,然后使用解引用运算符来解出y所使用的值:
1 | fn main() { |
我们使用&来引用一个变量,然后使用*来解引用这个变量
不可变引用
下面的代码,我们用 s1 的引用作为参数传递给 calculate_length 函数,而不是把 s1 的所有权转移给该函数:
1 | fn main() { |
我们注意到:
- 无需像上章一样:先通过函数参数传入所有权,然后再通过函数返回来传出所有权,代码更加简洁
calculate_length的参数s类型从String变为&String
在这里,&符号即是引用,他们允许你使用值,但是不获取所有权
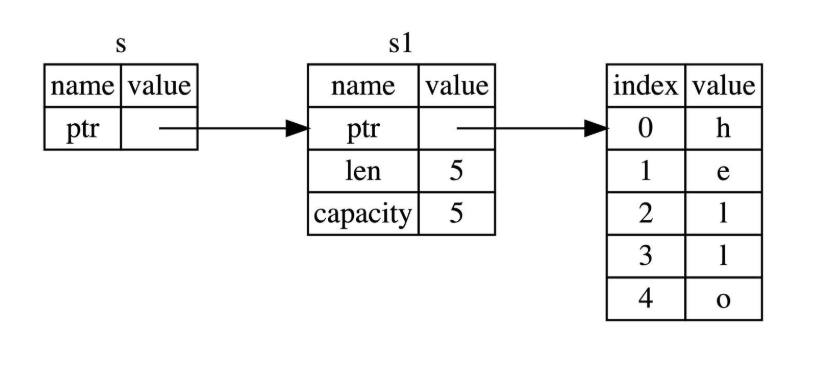
通过&s1语法,我们创建了一个指向s1的引用,但是并不拥有他。因为并不拥有这个值,当离开作用域后,其指向的值也不会被丢弃。
同理,函数 calculate_length 使用 & 来表明参数 s 的类型是一个引用:
1 | fn calculate_length(s: &String) -> usize { // s 是对 String 的引用 |
注意:借用的变量不可修改
1 | fn main() { |
这里尝试在s里添加,world,但是会报错
可变引用
我们知道用let直接定义的变量的值不可修改,但我们使用mut后,就可修改了
我们修改上面报错代码
1 | fn main() { |
输出hello,world
可变引用同时只能存在一个
不过可变引用并不是随心所欲、想用就用的,它有一个很大的限制: 同一作用域,特定数据只能有一个可变引用:
1 | let mut s = String::from("hello"); |
会报一个错
1 | error[E0499]: cannot borrow `s` as mutable more than once at a time 同一时间无法对 `s` 进行两次可变借用 |
这段代码出错的原因在于,第一个可变借用 r1 必须要持续到最后一次使用的位置 println!在 r1 创建和最后一次使用之间,我们又尝试创建第二个可变借用 r2。
我们改写成下面这种形式
1 | fn main() { |
这就避免了在同一时间有多个可变引用指向数据,r1变量在println!后就离开作用域了,后面只存在r2一个可变引用指向数据
这种限制的好处就是使 Rust 在编译期就避免数据竞争,数据竞争可由以下行为造成:
- 两个或更多的指针同时访问同一数据
- 至少有一个指针被用来写入数据
- 没有同步数据访问的机制
数据竞争会导致未定义行为,这种行为很可能超出我们的预期,难以在运行时追踪,并且难以诊断和修复。而 Rust 避免了这种情况的发生,因为它甚至不会编译存在数据竞争的代码!
很多时候,大括号可以帮我们解决一些编译不通过的问题,通过手动限制变量的作用域:
1 | let mut s = String::from("hello"); |
可变引用与不可变引用不能同时存在
1 | let mut s = String::from("hello"); |
总的来说,借用规则如下:
- 同一时刻,你只能拥有要么一个可变引用,要么任意多个不可变引用
- 引用必须总是有效的
悬垂引用
悬垂引用也叫做悬垂指针,意思为指针指向某个值后,这个值被释放掉了,而指针仍然存在,其指向的内存可能不存在任何值或已被其它变量重新使用。在 Rust 中编译器可以确保引用永远也不会变成悬垂状态:当你获取数据的引用后,编译器可以确保数据不会在引用结束前被释放,要想释放数据,必须先停止其引用的使用。
复合类型
字符串与切片
切片
切片并不是Rust独有的,其他语言都有,它允许你引用集合中部分连续的元素序列
对于字符串来说,切片就是对String类型某一部分的引用
1 | let s = String::from("hello world"); |
hello没有引用整个String s,而是引用s的一部分内容,通过[0..5]的方式来指定
这就是创建切片的语法,使用方括号包括的一个序列:**[开始索引..终止索引]**
对于 let world = &s[6..11]; 来说,world 是一个切片,该切片的指针指向 s 的第 7 个字节(索引从 0 开始, 6 是第 7 个字节),且该切片的长度是 5 个字节。
在使用 Rust 的 .. range 序列语法时,如果你想从索引 0 开始,可以使用如下的方式,这两个是等效的:
1 | let s = String::from("hello"); |
同样的,如果你的切片想要包含 String 的最后一个字节,则可以这样使用:
1 | let s = String::from("hello"); |
你也可以截取完整的 String 切片:
1 | let s = String::from("hello"); |
在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
2
3
let a = &s[0..2];
println!("{}",a);因为我们只取
s字符串的前两个字节,但是本例中每个汉字占用三个字节,因此没有落在边界处,也就是连中字都取不完整,此时程序会直接崩溃退出,如果改成&s[0..3],则可以正常通过编译。 因此,当你需要对字符串做切片索引操作时,需要格外小心这一点,关于该如何操作 UTF-8 字符串,参见这里。
当然,数组也可以切片
1 | let a = [1, 2, 3, 4, 5]; |
String和&str转换
&str 类型生成 String 类型的操作:
String::from("hello,world")"hello,world".to_string()
那如何将String类型转换成&str
1 | fn main() { |
String和&str区别
| 特性 | &str |
String |
|---|---|---|
| 内存分配 | 通常不涉及堆分配,指向现有内存或字符串字面量 | 在堆上分配内存,存储和管理自己的数据 |
| 可变性 | 不可变的字符串切片 | 可变字符串,可以修改其内容 |
| 生命周期 | &str 的生命周期依赖于引用的源 |
String 是所有权类型,生命周期与所有权相关 |
| 性能 | 更高效,不需要堆分配内存 | 相比 &str 有额外的堆分配和内存管理开销 |
| 常见用途 | 只读字符串,不需要修改 | 需要修改或动态生成字符串 |
字符串索引
1 | let s1 = String::from("hello"); |
会报错
注意:rust不存在字符串索引
字符串操作
追加(push)
push追加字符
push_str追加字符串
这两个方法都是在原有的字符串上追加,并不会返回新的字符串。由于字符串追加操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
1 | fn main() { |
插入(insert)
insert()插入単个字符
insert_str()插入字符串
这俩方法需要传入两个参数,第一个参数是字符(串)插入位置的索引,第二个参数是要插入的字符(串),索引从 0 开始计数,如果越界则会发生错误。由于字符串插入操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
1 | fn main() { |
替换(replace)
1.replace
适用于String和&str类型,replace()方法接收两个参数,第一个是要被替换的字符,第二个是新的字符串,该方法会匹配到所有的字符串。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
1 | fn main() { |
2.replacen
该方法可适用于 String 和 &str 类型。replacen() 方法接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数。该方法是返回一个新的字符串,而不是操作原来的字符串。
1 | fn main() { |
3.replace_range
该方法仅适用于String类型。replace_range接受两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符。
该方法是直接操作原来的字符串,不会返回新的字符串。该方法需要使用 mut 关键字修饰。
示例代码如下:
1 | fn main() { |
删除(delete)
与删除有关的方法有4个,pop(),remove(),truncate(),clear().这四个方法仅适用于String类型
1.pop –删除并返回字符串的最后一个字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是一个 Option 类型,如果字符串为空,则返回 None。
1 | fn main() { |
2.remove –删除并返回字符串中指定位置的字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串,只接收一个参数,表示该字符起始索引位置。
1 | fn main() { |
3.truncate –删除字符串中从指定位置开始到结尾的全部字符
该方法是直接操作原来的字符串。无返回值。该方法 truncate() 方法是按照字节来处理字符串的
1 | fn main() { |
4.clear –清空字符串
该方法是直接操作原来的字符串。调用后,删除字符串中的所有字符,相当于 truncate() 方法参数为 0 的时候。
1 | fn main() { |
连接 (Concatenate)
使用+或者+=连接字符串
在使用 + 时, 必须传递切片引用类型。不能直接传递 String 类型。**+ 是返回一个新的字符串,所以变量声明可以不需要 mut 关键字修饰**。
元组
定义:
长度固定、元素顺序固定
1 | fn main() { |
用模式匹配解构元组
将tup里的值分别赋值给x,y,z
1 | fn main() { |
用.来访问元组
如果我们想要访问某个特定的元素,我们使用.进行访问
1 | fn main() { |
和其他语言一样,元组的索引从0开始。
结构体
定义
一个结构体由几部分组成:
- 通过关键字
struct定义 - 一个清晰明确的结构体
名称 - 几个有名字的结构体
字段
例如:
1 | struct User { |
实例化
我们尝试实例化上面一个结构体
1 | let user1 = User { |
有几点值得注意:
- 初始化实例时,每个字段都需要进行初始化
- 初始化时的字段顺序不需要和结构体定义时的顺序一致
访问结构体字段
1 | let mut user1 = User { |
我们用.来访问和修改结构体实例内部的字段值
需要注意的是,必须要将结构体实例声明为可变的,才能修改其中的字段
简化结构体构造
下面的函数类似一个构建函数,返回了 User 结构体的实例:
1 | fn build_user(email: String, username: String) -> User { |
它接收两个字符串参数: email 和 username,然后使用它们来创建一个 User 结构体,并且返回。可以注意到这两行: email: email 和 username: username,非常的扎眼,因为实在有些啰嗦,如果你从 TypeScript 过来,肯定会鄙视 Rust 一番,不过好在,它也不是无可救药:
1 | fn build_user(email: String, username: String) -> User { |
如上所示,当函数参数和结构体字段同名时,可以直接使用缩略的方式进行初始化,跟 TypeScript 中一模一样。
结构体更新语法
根据已有的结构体实例,创建新的结构体实例,例如根据已有的 user1 实例来构建 user2:
1 | let user2 = User { |
我们发现,user1的三个字段居然手动被赋值给了user2,太麻烦了,Rust提供了结构体更新语法:
1 | let user2 = User { |
只需用一个..,就能将与user1一样的值赋给了user2
元组结构体(tuple struct)
结构体必须要有名称,但是结构体的字段可以没有名称,这种结构体长得像元组,因此称为元组结构体: struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
元组结构体在你希望有一个整体名称,但是又不关心里面字段的名称时将非常有用。例如上面的 Point 元组结构体,众所周知 3D 点是 (x, y, z) 形式的坐标点,因此我们无需再为内部的字段逐一命名为:x, y, z。
单元结构体
单元结构体和单元类型很像,没有任何字段和属性
如果你定义一个类型,但是不关心该类型的内容,只关心它的行为时,就可以使用 单元结构体:
使用 #[derive(Debug)] 来打印结构体的信息
如果我们想要对一个结构体实例进行打印,需要在代码最前方加上一个#[derive(Debug)] ,然后使用dbg!()或者println!("{:?}", s);来输出
1 |
|
枚举
枚举允许你通过列举可能的成员来定义一个枚举类型,例如扑克牌花色:
1 | enum PokerSuit { |
枚举类型是一个类型,它会包含所有可能的枚举成员,而枚举值是该类型中的具体某个成员的实例。
枚举值
我们通过::来访问枚举类型下的具体成员
1 | let heart = PokerSuit::Hearts; |
接下来,我们想让扑克牌变得更加实用,那么需要给每张牌赋予一个值:A(1)-K(13),这样再加上花色,就是一张真实的扑克牌了,例如红心 A。
目前来说,枚举值还不能带有值,因此先用结构体来实现:
1 | enum PokerSuit { |
这段代码很好的完成了它的使命,通过结构体 PokerCard 来代表一张牌,结构体的 suit 字段表示牌的花色,类型是 PokerSuit 枚举类型,value 字段代表扑克牌的数值。
可以吗?可以!好吗?说实话,不咋地,因为还有简洁得多的方式来实现:
1 | enum PokerCard { |
直接将数据信息关联到枚举成员上,省去近一半的代码,这种实现是不是更优雅?
不仅如此,同一个枚举类型下的不同成员还能持有不同的数据类型,例如让某些花色打印 1-13 的字样,另外的花色打印上 A-K 的字样:
1 | enum PokerCard { |
同一化类型
枚举(enum)是 Rust 中一种常用的类型,它可以将不同类型的数据统一为一个枚举类型。通过定义不同的枚举变体,可以将多种类型的数据封装在一个类型中,然后使用模式匹配来解构和统一处理它们。
例如我们有一个 WEB 服务,需要接受用户的长连接,假设连接有两种:TcpStream 和 TlsStream,但是我们希望对这两个连接的处理流程相同,也就是用同一个函数来处理这两个连接,代码如下:
1 | fn new (stream: TcpStream) { |
此时,枚举类型就能帮上大忙:
1 | enum Websocket { |
数组
在Rust中,最常用的数组有两种,第一种是速度很快但是长度固定的array,第二种是可动态增长的但是有性能损耗的Vector,我们将前面的array称之为数组,将后面的Vector称之为动态数组
数组的具体定义很简单:将多个类型相同的元素依次组合在一起,就是一个数组,数组具有以下三要素:
- 长度固定
- 元素必须有相同的类型
- 依次线性排列
我们这里说的数组是 Rust 的基本类型,是固定长度的,这点与其他编程语言不同,其它编程语言的数组往往是可变长度的,与 Rust 中的动态数组 Vector 类似
创建数组
1 | fn main() { |
访问数组元素
更其他语言一样,用索引来访问
1 | fn main() { |
访问数组的第一个元素
注意:数组元素是非基本类型
数组切片
1 | let a: [i32; 5] = [1, 2, 3, 4, 5]; |
上面的数组切片 slice 的类型是&[i32],与之对比,数组的类型是[i32;5],简单总结下切片的特点:
- 切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
- 创建切片的代价非常小,因为切片只是针对底层数组的一个引用
- 切片类型 [T] 拥有不固定的大小,而切片引用类型 &[T] 则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此 &[T] 更有用,
&str字符串切片也同理
流程控制(语句学习)
1.if语句
1 | if condition == true { |
2.if-else语句
1 | fn main() { |
3.for循环
1 | fn main() { |
1..=5的意思是1到5(包括5),1..5意思是1到5(不包括5)
注意,使用 for 时我们往往使用集合的引用形式,除非你不想在后面的代码中继续使用该集合(比如我们这里使用了 container 的引用)。如果不使用引用的话,所有权会被转移(move)到 for 语句块中,后面就无法再使用这个集合了):
1 | for item in &container { |
如果想在循环中,修改该元素,可以使用 mut 关键字:
1 | for item in &mut collection { |
总结如下:
| 使用方法 | 等价使用方式 | 所有权 |
|---|---|---|
for item in collection |
for item in IntoIterator::into_iter(collection) |
转移所有权 |
for item in &collection |
for item in collection.iter() |
不可变借用 |
for item in &mut collection |
for item in collection.iter_mut() |
可变借用 |
如果想在循环中获取元素的索引:
1 | fn main() { |
当然如果我们想用 for 循环控制某个过程执行 10 次,但是又不想单独声明一个变量来控制这个流程
我们用_来代替那个变量
1 | for _ in 0..10 { |
4.continue
使用continue可以跳过当前循环,开始下一次循环
1 | for i in 1..4 { |
5.break
使用break跳出当前整个循环
1 | for i in 1..4 { |
6.while循环
跟c的差不多
1 | fn main() { |
7.loop循环
简单的无限循环,我们可以在其内部设置break决定何时结束循环
1 | fn main() { |
1 | fn main() { |
这里有几点值得注意:
- break 可以单独使用,也可以带一个返回值,有些类似
return - loop 是一个表达式,因此可以返回一个值
模式匹配
match和if let
match匹配
先看看match的通用形式:
1 | match target { |
match 允许我们将一个值与一系列的模式相比较,并根据相匹配的模式执行对应的代码
我们来看一个例子
1 | enum Coin { |
value_in_cents函数根据匹配到的硬币,返回对应的美分数值。match后紧跟着的是一个表达式,跟if很像,但是if后的表达式必须是一个布尔值,而match后的表达式返回值可以是任意类型,只要能跟后面的分支中的模式匹配起来即可,这里的coin是枚举Coin类型接下来是match的分支。一个分支有两个部分:一个模式和针对该模式的处理代码。第一个分支的模式是
Coin::Penny,其后的=>运算符将模式和将要运行的代码分开。这里的代码就仅仅是表达式1,不同分支之间使用逗号分隔。当
match表达式执行时,它将目标值coin按顺序依次与每一个分支的模式相比较,如果模式匹配了这个值,那么模式之后的代码将被执行。如果模式并不匹配这个值,将继续执行下一个分支。每个分支相关联的代码是一个表达式,而表达式的结果值将作为整个
match表达式的返回值。如果分支有多行代码,那么需要用{}包裹,同时最后一行代码需要是一个表达式。
简单来说就是在下面main中的传入value_in_cents的值,匹配到啥,就输出啥
模式绑定
模式匹配的另外一个重要功能是从模式中取出绑定的值,例如:
1 |
|
其中 Coin::Quarter 成员还存放了一个值:美国的某个州(因为在 1999 年到 2008 年间,美国在 25 美分(Quarter)硬币的背后为 50 个州印刷了不同的标记,其它硬币都没有这样的设计)。
接下来,我们希望在模式匹配中,获取到 25 美分硬币上刻印的州的名称:
1 | fn value_in_cents(coin: Coin) -> u8 { |
上面代码中,在匹配 Coin::Quarter(state) 模式时,我们把它内部存储的值绑定到了 state 变量上,因此 state 变量就是对应的 UsState 枚举类型。
例如有一个印了阿拉斯加州标记的 25 分硬币:Coin::Quarter(UsState::Alaska),它在匹配时,state 变量将被绑定 UsState::Alaska 的枚举值。
穷尽匹配
之前说过match的匹配必须穷尽所有情况,下面来距离说明。例如:
1 | enum Direction { |
上述代码中,我们匹配了East,North,South,但没有匹配West,程序就会报一个错
1 | error[E0004]: non-exhaustive patterns: `West` not covered // 非穷尽匹配,`West` 没有被覆盖 |
所以我们在写模式匹配时,需要将所有枚举的值都赋上值
_通配符
当我们不想在匹配时列出所有值的时候,可以使用Rust提供的一个特殊模式,例如,u8 可以拥有 0 到 255 的有效的值,但是我们只关心 1、3、5 和 7 这几个值,不想列出其它的 0、2、4、6、8、9 一直到 255 的值。那么, 我们不必一个一个列出所有值, 因为可以使用特殊的模式 _ 替代:
1 | let some_u8_value = 0u8; |
通常,将_防止其他分支后,_将会匹配所有遗漏的值。()表示返回单元类型与所有分支返回值的类型相同,所以当匹配到_后,什么也不会发生
除了_通配符,用一个变量来承载其他情况也是可以的。
1 |
|
然而,在某些场景下,我们其实只关心某一个值是否存在,此时 match 就显得过于啰嗦。
if let匹配
在 Rust 中,Some 是 Option 枚举的一个变体。Option 是一个非常常用的枚举类型,它用于表示一个可能存在或不存在的值。Option 有两个变体:
Some(T):表示一个包含类型T的值。Some用来包装一个具体的值,表示该值存在。None:表示没有值,也就是值不存在。
有时候会遇到只有一个模式的值需要被处理,其他值被忽略的情况,如果使用match就要写成一下模式
1 | let v = Some(3u8); |
这样写太过于繁冗,我们使用if let的方式来实现
1 | if let Some(3) = v { |
matches!宏
Rust标准库中提供了一个非常实用的宏:matches!,他可以将一个表达式跟模式进行匹配,然后返回匹配的结果 true or false。
例如,有一个动态数组,里面存有以下枚举
1 | enum MyEnum { |
现在如果想对v进行过滤,只保留类型是MyEnum::Foo的元素,按经验一般来说是这样写的
1 | v.iter().filter(|x| x == MyEnum::Foo); |
但是,实际上这行代码会报错,因为你无法将x直接跟一个枚举成员进行比较。我们使用matches!进行比较
1 | v.iter().filter(|x| matches!(x, MyEnum::Foo)); |
我们来看看其他例子
1 | let foo = 'f'; |
变量遮蔽
无论是 match 还是 if let,这里都是一个新的代码块,而且这里的绑定相当于新变量,如果你使用同名变量,会发生变量遮蔽:
1 | fn main() { |
cargo run 运行后输出如下:
1 | 在匹配前,age是Some(30) |
可以看出在 if let 中,= 右边 Some(i32) 类型的 age 被左边 i32 类型的新 age 遮蔽了,该遮蔽一直持续到 if let 语句块的结束。因此第三个 println! 输出的 age 依然是 Some(i32) 类型。
对于 match 类型也是如此:
1 | fn main() { |
需要注意的是,**match 中的变量遮蔽其实不是那么的容易看出**,因此要小心!其实这里最好不要使用同名,避免难以理解
解构Option
定义:
1 | enum Option<T> { |
简单解释就是,应该变量要么有值:Some(T),要么为空:None.
那现在我们该如何去使用这个Option枚举类型,根据经验,可以通过match来实现
因为
Option,Some,None都包含在prelude中,因此你可以直接通过名称来使用它们,而无需以Option::Some这种形式去使用,总之,千万不要因为调用路径变短了,就忘记Some和None也是Option底下的枚举成员!
匹配Option<T>
使用Option<T>,是为了从Some中取出起内部的T值以及处理没有值的情况,为了演示这一点,下面编写一个函数,它获取一个Option<i32>,如果其中含有一个值,将其加一;如果其中没有值,则返回None值;
1 | fn plus_one(x: Option<i32>) -> Option<i32> { |
plus_one接受一个Option<i32>类型的参数,提示返回一个Option<i32>类型的值(这种形式的函数在标准库类随处可见),在该函数的内部处理中,如果传入的是一个None,则返回一个None且不做任何处理;如果传入的是一个Some(i32),则通过模式绑定,把其中的值绑定到变量i上,然后返回i+1的值,同时用Some进行包裹
当传入Some(5)时,首先匹配None分支,由于值不满足,继续匹配下一个分支:
1 | Some(i) => Some(i + 1) |
Some(5)与Some(i)匹配上了,i绑定了Some包含的值,因此i在这里i的值为5,接着匹配分支的代码被执行,最后将i的值加一并返回一个含有值6的新Some。
当传入None时,直接就匹配到了match的第一个分支,后续分支将不再匹配
模式匹配适用场景
match分支
1 | match VALUE { |
如上所示,match的每一个分支就是一个模式,因为match是无穷尽,因此我们需要一个_通配符来匹配剩余所有情况:
1 | match VALUE { |
if let分支
if let 分支往往用于匹配一个模式,而忽略剩下所有模式的场景:
1 | if let PATTERN = SOME_VALUE { |
while let条件循环
它只允许条件满足,模式匹配就能一直进行while循环。
1 |
|
for循环
1 | let v = vec!['a', 'b', 'c']; |
这里使用enumerate方法生成了一个迭代器,该迭代器每次迭代都会返回一个(索引,值)形式的元组,然后用(index,value)来匹配
let语句
1 | let PATTERN = EXPRESSION; |
该语句也是一种模式匹配
1 | let x = 5; |
这其中,x是一种模式绑定,代表将匹配的值绑定到变量上,因此,在Rust中,变量名也是一种模式,只不过它比较朴素很不起眼罢了
函数参数
函数参数也是模式:
1 | fn foo(x: i32) { |
其中x就是一个模式,你还可以在参数中匹配元组:
1 | fn print_coordinates(&(x, y): &(i32, i32)) { |
&(3,5)会匹配模式&(x,y),因此x得到了3,y得到了5
let和if let
对于以下代码,编译器会报错:
1 | let Some(x) = some_option_value; |
因为右边的值可能不为Some,而是None,这种时候就不能进行匹配,也就是上面的代码遗漏None的匹配
类似let,for和match都必须要求完全覆盖匹配,才能通过编译(不可驳模式匹配)
但是对于if let,就可以这样使用:
1 | if let Some(x) = some_option_value{ |
因为if let允许匹配一种模式,而忽略区域的模式(可驳模式匹配)。
let-else(Rust 1.65 新增)
使用 let-else 匹配,即可使 let 变为可驳模式。它可以使用 else 分支来处理模式不匹配的情况,但是 else 分支中必须用发散的代码块处理(例如:break、return、panic)
全模式列表(总结)
由于不同类型的模式匹配的例子比较多,为了方便查询,总结一下
匹配字面值
1 | let x = 1; |
匹配命名变量
在match中存在变量遮蔽问题,这个在匹配命名变量时会遇到
1 | fn main() { |
当match运行时,第一个匹配分支的模式并不匹配x中定义的值,所以代码继续执行
第二个匹配分支中的模式引入了一个新的变量y,他会匹配some的任何值,由于这里的y在match表达式的作用域总,所以这是一个新变量,而不是开头声明的y
如果 x 的值是 None 而不是 Some(5),头两个分支的模式不会匹配,所以会匹配模式 _。这个分支的模式中没有引入变量 x,所以此时表达式中的 x 会是外部没有被遮蔽的 x,也就是 None。
如果你不想引入变量遮蔽,可以使用另一个变量名而非 y,或者使用匹配守卫(match guard)的方式,稍后在匹配守卫提供的额外条件中会讲解。
单支多模式
在match表达式中,可以使用|语法匹配多个模式
1 | let x = 1; |
上面的代码会打印one or two
通过..=匹配值的范围
在数值类型中我们有讲到一个序列语法,该语法不仅可以用于循环中,还能用于匹配模式
1 | let x = 5; |
如果x的值是1,2,3,4,5就会匹配到1..=5
解构并分解值
也可以使用模式来解构结构体、枚举、元组、数组和引用
解构结构体
1 | struct Point { |
这段代码创建了变量a,b来匹配结构体p中的x和y
字段,这个例子展示了模式中的变量名不必与结构体中的字段名一致。不过通常希望变量名与字段名一致以便于理解变量来自于哪些字段。
解构枚举
下面代码以 Message 枚举为例,编写一个 match 使用模式解构每一个内部值:
1 | enum Message { |
这里老生常谈一句话,模式匹配一样要类型相同,因此匹配 Message::Move{1,2} 这样的枚举值,就必须要用 Message::Move{x,y} 这样的同类型模式才行。这段代码会打印出 Change the color to red 0, green 160, and blue 255。尝试改变 msg 的值来观察其他分支代码的运行。
解构嵌套的结构体和枚举
目前为止,所有的例子都只匹配了深度为一级的结构体或枚举。 match 也可以匹配嵌套的项!
例如使用下面的代码来同时支持 RGB 和 HSV 色彩模式:
1 | enum Color { |
match 第一个分支的模式匹配一个 Message::ChangeColor 枚举成员,该枚举成员又包含了一个 Color::Rgb 的枚举成员,最终绑定了 3 个内部的 i32 值
解构结构体和元组
我们可以用复杂的方式来混合、匹配和嵌套解构模式。如下是一个复杂结构体的例子,其中结构体和元组嵌套在元组中,并将所有的原始类型解构出来
1 | struct Point { |
解构数组
对于数组,我们可以用类似元组的方式进行解构,分为两种情况
定长数组:
1 | let arr: [u16; 2] = [114, 514]; |
不定长数组
1 | let arr: &[u16] = &[114, 514]; |
忽略模式中的值
又是忽略模式的一些值也是很有用的,比如在match中的最后一个分支使用_模式匹配所有剩余的值。也可以在另一个模式中使用_模式,使用一个亿下划线开始的名称,或者使用..忽略所剩部分的值
使用_忽略整个值
虽然 _ 模式作为 match 表达式最后的分支特别有用,但是它的作用还不限于此。例如可以将其用于函数参数中:
1 | fn foo(_: i32, y: i32) { |
这段代码会完全忽略作为第一个参数传递的值 3,并会打印出 This code only uses the y parameter: 4。
大部分情况当你不再需要特定函数参数时,最好修改签名不再包含无用的参数。在一些情况下忽略函数参数会变得特别有用,比如实现特征时,当你需要特定类型签名但是函数实现并不需要某个参数时。此时编译器就不会警告说存在未使用的函数参数,就跟使用命名参数一样。
使用嵌套的_忽略部分值
可以在一个模式内部使用_忽略部分值
1 | let mut setting_value = Some(5); |
这段代码会打印出 Can't overwrite an existing customized value 接着是 setting is Some(5)。
第一个匹配分支,我们不关心里面的值,只关心元组中两个元素的类型,因此对于 Some 中的值,直接进行忽略。 剩下的形如 (Some(_),None),(None, Some(_)), (None,None) 形式,都由第二个分支 _ 进行分配。
使用下划线忽略未使用的变量
如果你创建了一个变量却不在任何地方使用它就需要使用_放在变量开头来忽略它
注意, 只使用 _ 和使用以下划线开头的名称有些微妙的不同:比如 _x 仍会将值绑定到变量,而 _ 则完全不会绑定。
1 | let s = Some(String::from("Hello!")); |
s 是一个拥有所有权的动态字符串,在上面代码中,我们会得到一个错误,因为 s 的值会被转移给 _s,在 println! 中再次使用 s 会报错:
1 | s 是一个拥有所有权的动态字符串,在上面代码中,我们会得到一个错误,因为 s 的值会被转移给 _s,在 println! 中再次使用 s 会报错: |
只使用下滑线本身就不会绑定值了,因为s没有移动进_:
1 | let s = Some(String::from("Hello!")); |
匹配守卫提供的额外条件
匹配守卫是一个位于match分支模式之后的额外的if条件,它能为分支模式提供更进一步的匹配条件
这个条件可以使用模式中创建的变量:
1 | let num = Some(4); |
这个例子会打印出 less than five: 4。当 num 与模式中第一个分支匹配时,Some(4) 可以与 Some(x) 匹配,接着匹配守卫检查 x 值是否小于 5,因为 4 小于 5,所以第一个分支被选择。
相反如果 num 为 Some(10),因为 10 不小于 5 ,所以第一个分支的匹配守卫为假。接着 Rust 会前往第二个分支,因为这里没有匹配守卫所以会匹配任何 Some 成员。
模式中无法提供类如 if x < 5 的表达能力,我们可以通过匹配守卫的方式来实现。
@绑定
@运算符允许为一个字段绑定另外一个变量。下面例子中,我们希望测试Message::hello的id字段是否位于3..=7的范围内,同时也希望能将其值绑定到 id_variable 变量中以便此分支中相关的代码可以使用它。我们可以将 id_variable 命名为 id,与字段同名,不过出于示例的目的这里选择了不同的名称。
1 | enum Message { |
上例会打印出 Found an id in range: 5。通过在 3..=7 之前指定 id_variable @,我们捕获了任何匹配此范围的值并同时将该值绑定到变量 id_variable 上。
第二个分支只在模式中指定了一个范围,id 字段的值可以是 10、11 或 12,不过这个模式的代码并不知情也不能使用 id 字段中的值,因为没有将 id 值保存进一个变量。
最后一个分支指定了一个没有范围的变量,此时确实拥有可以用于分支代码的变量 id,因为这里使用了结构体字段简写语法。不过此分支中没有像头两个分支那样对 id 字段的值进行测试:任何值都会匹配此分支。
当你既想要限定分支范围,又想要使用分支的变量时,就可以用 @ 来绑定到一个新的变量上,实现想要的功能。
@前绑定后解构(Rust 1.56 新增)
使用 @ 还可以在绑定新变量的同时,对目标进行解构:
1 |
|
@新特性(Rust 1.53 新增)
考虑下面一段代码:
1 | fn main() { |
编译不通过,是因为 num 没有绑定到所有的模式上,只绑定了模式 1,你可能会试图通过这个方式来解决:
1 | num @ (1 | 2) |
但是,如果你用的是 Rust 1.53 之前的版本,那这种写法会报错,因为编译器不支持。
至此,模式匹配的内容已经全部完结,复杂但是详尽,想要一次性全部记住属实不易,因此读者可以先留一个印象,等未来需要时,再来翻阅寻找具体的模式实现方式。
方法Method
定义方法
Rust使用impl来定义方法,例如以下代码:
1 | struct Circle { |
我们来看看Rust和其它语言的区别:

我们可以看到其它语言中所有定义都在class中,但是Rust的对象定义和方法定义是分离的,这种数据和使用分离的方式会给使用者极高的灵活度
我们来看下面例子
1 |
|
该例子定义了一个Rectangle结构体,并且在其定义了一个area方法,用于计算该矩阵的面积
impl Rectangle {} 表示为 Rectangle 实现方法(impl 是实现 implementation 的缩写),这样的写法表明 impl 语句块中的一切都是跟 Rectangle 相关联的。
self、&self和&mut self
在area的签名中,我们使用&self替代rectangle:&Rectangle,&self其实是self:&Self的简写(注意大小写)。在一个impl快内,Self指代被实现方法的结构体内向,self指代此类型的实例
换句话说,self指代的是Rectangle结构体实例,这样的写法会让代码简洁好多
需要注意的是,self 依然有所有权的概念:
self表示Rectangle的所有权转移到该方法中,这种形式用的较少&self表示该方法对Rectangle的不可变借用&mut self表示可变借用
我们并不想获取所有权,也无需去改变它,只是希望能够读取结构体中的数据就使用&self,而当我们需要去改变当前结构体时,就需要使用&mut self
简单总结下,使用方法代替函数有以下好处:
- 不用在函数签名中重复书写
self对应的类型 - 代码的组织性和内聚性更强,对于代码维护和阅读来说,好处巨大
方法名跟结构体字段名相同
在Rust中,允许方法名跟结构体字段名相同:
1 | impl Rectangle { |
当我们使用 rect1.width() 时,Rust 知道我们调用的是它的方法,如果使用 rect1.width,则是访问它的字段。
带多个参数的方法
方法和函数一样, 可以使用多个参数:
1 | impl Rectangle { |
关联函数
如何为一个结构体定义一个构造器方法?也就是接受几个参数,然后构造并返回该结构体的实例,很简单,参数中不包含 self 即可
这种定义在 impl 中且没有 self 的函数被称之为关联函数: 因为它没有 self,不能用 f.read() 的形式调用,因此它是一个函数而不是方法,但它又在impl中,与结构体紧密关联,因此称为关联函数
1 | impl Rectangle { |
多个impl定义.
Rust 允许我们为一个结构体定义多个 impl 块,目的是提供更多的灵活性和代码组织性,例如当方法多了后,可以把相关的方法组织在同一个 impl 块中,那么就可以形成多个 impl 块,各自完成一块儿目标:
1 | impl Rectangle { |
为枚举实现方法
枚举类型之所以强大,不仅仅在于它好用、可以同一化类型,还在于,我们可以像结构体一样,为枚举实现方法:
1 |
|
除了结构体和枚举,我们还能为特征(trait)实现方法,在此之前,先来看看泛型。
泛型和特征
泛型Generics
1 | fn add<T>(a:T, b:T) -> T { |
上面的代码T就是泛型参数,实际上在Rust中,泛型参数的名称可以随便起,但是出于惯例,我们都是用T来作为首选
使用泛型参数,有一个先决条件,必需在使用前对其进行声明:
1 | fn largest<T>(list: &[T]) -> T { |
该泛型函数的作用是从列表中找出最大的值,其中列表中的元素类型为 T。首先 largest<T> 对泛型参数 T 进行了声明,然后才在函数参数中进行使用该泛型参数 list: &[T] (还记得 &[T] 类型吧?这是数组切片)。
总之,我们可以这样理解这个函数定义:函数 largest 有泛型类型 T,它有个参数 list,其类型是元素为 T 的数组切片,最后,该函数返回值的类型也是 T。
显式地指定泛型的类型参数
有时候,编译器无法推断你想要的泛型参数:
1 | use std::fmt::Display; |
上面代码直接运行会报错,我们修改代码,使用显式指定类型:
1 | use std::fmt::Display; |
结构体中使用泛型
结构体中的字段类型也可以用泛型来定义,下面的代码定义了一个坐标点Point,它可以存放任何类型的坐标值
1 | struct Point<T>{ |
这里有两点需要注意
- 提前声明,跟泛型函数定义类似,首先我们在使用泛型参数之前必需要进行声明
Point<T>,接着就可以在结构体的字段类型中使用T来替代具体的类型 - x 和 y 是相同的类型
第二点非常重要,如果使用不同的类型,那么它会导致下面代码的报错:
1 | struct Point<T> { |
x是整数类型,y是浮点数类型的,会发生报错
如果我们想要x,y既能类型相同,又能类型不同,那我们需要使用不同的泛型参数:
1 | struct Point<T,U> { |
切记,所有的泛型参数都要提前声明:Point<T,U> ! 但是如果你的结构体变成这鬼样:struct Woo<T,U,V,W,X>,那么你需要考虑拆分这个结构体,减少泛型参数的个数和代码复杂度。
枚举中使用泛型
提到枚举类型,Option永远是第一个应该被想起来的
1 | enum Option<T> { |
Option
得益于泛型的引入,我们可以在任何一个需要返回值的函数中,去使用 Option<T> 枚举类型来做为返回值,用于返回一个任意类型的值 Some(T),或者没有值 None。
对于枚举而言,卧龙凤雏永远是绕不过去的存在:如果是 Option 是卧龙,那么 Result 就一定是凤雏,得两者可得天下:
1 | enum Result<T, E> { |
这个枚举和Option一样,主要用于函数返回值,与Option用于值的存在与否不同,Result关注的主要是值的正确性。
方法中使用泛型
1 | struct Point<T> { |
使用泛型参数前,依然需要提前声明:impl<T>,只有提前声明了,我们才能在Point<T>中使用它,这样Rust就知道Point的尖括号中的类型是泛型而不是具体类型。这里需要注意的是,这里的Point<T>不在是泛型声明,而是一个完整的结构体类型,因为我们定义的结构体是Point<T>,而不是Point
为具体的泛型实现方法
对于 Point<T> 类型,你不仅能定义基于 T 的方法,还能针对特定的具体类型,进行方法定义:
1 | impl Point<f32> { |
这段代码意味着 Point<f32> 类型会有一个方法 distance_from_origin,而其他 T 不是 f32 类型的 Point<T> 实例则没有定义此方法。这个方法计算点实例与坐标(0.0, 0.0) 之间的距离,并使用了只能用于浮点型的数学运算符。
这样我们就能针对特定的泛型类型实现某个特定的方法,对于其它泛型类型则没有定义该方法。
const泛型(Rust1.51版本引入的主要特征)
以上总结起来就是:针对类型实现的泛型,所有的泛型都是为了抽象不同的类型,那有没有针对值的泛型?
我们来看下面,在数组中说过[i32;2]和[i32;3]是不同的数组类型,比如下面的代码
1 | fn display_array(arr: [i32; 3]) { |
结合代码和报错,可以很清楚的看出,[i32; 3] 和 [i32; 2] 确实是两个完全不同的类型,因此无法用同一个函数调用。
首先,让我们修改代码,让display_array能打印任意长度的i32数组:
1 | fn display_array(arr: &[i32]) { |
很简单,只要使用数组切片,然后传入arr的不可变引用即可
接着,将i32改成所有类型的数组:
1 | fn display_array<T: std::fmt::Debug>(arr: &[T]) { |
这里需要注意的是需要对T加一个限制std::fmt::Debug,该限制表明T可以用在println!(“{:?}”,arr)中,因为{:?}形式的格式化输出需要arr实现该特征
通过引用,我们可以很轻松的解决处理任何类型数组的问题,但是如果在某些场景下引用不适宜用或者干脆不能用呢?你们知道为什么以前 Rust 的一些数组库,在使用的时候都限定长度不超过 32 吗?因为它们会为每个长度都单独实现一个函数,简直。。。毫无人性。难道没有什么办法可以解决这个问题吗?
好在,现在咱们有了 const 泛型,也就是针对值的泛型,正好可以用于处理数组长度的问题:
1 | fn display_array<T: std::fmt::Debug, const N: usize>(arr: [T; N]) { |
如上,我们对了一该类型为[T;N]的数组,其中T是一个基于类型的泛型参数,这个和之前讲的泛型没什么区别,而重点在于N,是一个基于值的泛型参数,因为它用来替代的是数组的长度。
N就是const泛型,定义的语法是const N:usize,表示const泛型N,它基于的值是usize
const泛型表达式
假设我们某个代码需要再内存很小的平台上工作,因此需要限制函数参数占用的内存大小,此时就可以使用const泛型表达式来实现:
1 | // 目前只能在nightly版本下使用 |
const fn
常量函数,const fn允许我们在编译期对函数进行求值,进而实现更高效、灵活的代码设计
作用:在某些场景下,我们希望在编译期就计算出一些值,以提高运行时的性能或满足某些编译期的约束条件。例如,定义数组的长度、计算常量值等。
const fn基本用法:
要定义一个常量函数,只需要在函数声明前加上const关键字
1 | const fn add(a: usize, b: usize) -> usize { |
const fn的限制
由于其在编译期执行,以确保函数能在编译期被安全地求值,因此有一些限制,例如,不可将随机数生成器写成 const fn
无论在编译时还是运行时调用const fn,它们的结果总是相同的,即是多次调用也一样。唯一的例外是,如果你在极端情况下进行复杂的浮点操作,可能会得到(非常轻微的)不同结构。因此,不建议使 数组长度 (arr.len()) 和 Enum判别式 依赖于浮点计算。
结合const fn与const泛型
将 const fn 与 const 泛型 结合,可以实现更加灵活和高效的代码设计。例如,创建一个固定大小的缓冲区结构,其中缓冲区大小由编译期计算确定:
1 | struct Buffer<const N: usize> { |
在这个例子中,compute_buffer_size 是一个常量函数,它根据传入的 factor 计算缓冲区的大小。在 main 函数中,我们使用 compute_buffer_size(4) 来计算缓冲区大小为 4096 字节,并将其作为泛型参数传递给 Buffer 结构体。这样,缓冲区的大小在编译期就被确定下来,避免了运行时的计算开销。
泛型的性能
Rust通过在编译时进行泛型代码的单态化来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用的代码转换为特定代码的国城
编译器所做的工作正好与我们创建泛型函数的步骤相反,编译器寻找所有泛型代码被调用的位置并针对具体类型生成代码。
我们来看看一个使用标准库中Option枚举的例子:
1 |
|
当 Rust 编译这些代码的时候,它会进行单态化。编译器会读取传递给 Option<T> 的值并发现有两种 Option<T>:一种对应 i32 另一种对应 f64。为此,它会将泛型定义 Option<T> 展开为 Option_i32 和 Option_f64,接着将泛型定义替换为这两个具体的定义。
编译器生成的单态化版本的代码看起来像这样:
1 | enum Option_i32 { |
我们可以使用泛型来编写不重复的代码,而 Rust 将会为每一个实例编译其特定类型的代码。这意味着在使用泛型时没有运行时开销;当代码运行,它的执行效率就跟好像手写每个具体定义的重复代码一样。这个单态化过程正是 Rust 泛型在运行时极其高效的原因。
特征Trait
跟接口类似
在之前的代码中,我们也多次见过特征的使用,例如 #[derive(Debug)],它在我们定义的类型(struct)上自动派生 Debug 特征,接着可以使用 println!("{:?}", x) 打印这个类型;再例如:
1 | fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T { |
通过 std::ops::Add 特征来限制 T,只有 T 实现了 std::ops::Add 才能进行合法的加法操作,毕竟不是所有的类型都能进行相加。
这些都说明一个道理,特征定义了一组可以被共享的行为,只要实现了特征,你就能使用这组行为。
定义
如果不同的类型具有相同的行为,那么我们就可以定义一个特征,然后为这些类型实现该特征。定义特征是把一些方法组合在一起,目的是定义一个实现某些目标所必需的行为的集合。
1 | pub trait Summary { |
这里使用 trait 关键字来声明一个特征,Summary 是特征名。在大括号中定义了该特征的所有方法,在这个例子中是: fn summarize(&self) -> String。
特征只定义行为看起来怎么样,而不对行为具体是怎么样的。因此,我们只定义特征方法的前面,而不进行实现,此时方法签名结尾是;,而不是一个{}
为类型实现特征
1 | pub trait Summary { |
实现特征的语法与为结构体、枚举实现方法很像:impl Summary for Post,我们把它称做”为Post类型实现Summary特征”,然后在impl内实现该特征的具体方法
接下来就是调用特征方法:
1 | fn main() { |
特性定义与实现的位置(孤儿法则)
上面我们将Summary定义成了pub公开的,这样,如果他人想要使用我们的 Summary 特征,则可以引入到他们的包中,然后再进行实现。
关于特征实现与定义的位置,如果你想要为类型A实现特征T,那么A或者T至少有一个是在当前作用域中定义的,例如我们可以为上面的 Post 类型实现标准库中的 Display 特征,这是因为 Post 类型定义在当前的作用域中。同时,我们也可以在当前包中为 String 类型实现 Summary 特征,因为 Summary 定义在当前作用域中。
但是你无法在当前作用域中,为 String 类型实现 Display 特征,因为它们俩都定义在标准库中,其定义所在的位置都不在当前作用域,跟你半毛钱关系都没有,看看就行了。
该规则被称为孤儿规则,可以确保其它人编写的代码不会破坏你的代码,也确保了你不会莫名其妙就破坏了风马牛不相及的代码
默认实现
我们可以在特征中定义具有默认实现的方法,这样其它类型无需再实现该方法,或者也可以选择重载该方法:
1 | pub trait Summary { |
上面为Summary定义了一个默认实现,下面我们编写段代码来测试:
1 | impl Summary for Post {} |
我们发现post使用了默认实现,而Weibo重载了该方法
默认实现允许调用相同特征中的其他方法,哪怕这些方法没有默认实现。如此,特征可以提供很多有用的功能而只需要实现指定的一小部分内容。
使用特征作为函数参数
之前提到,特征仅仅是用来实现方法,有些浪费
现在来定义一个函数,使用特征作为函数参数:
1 | pub fn notify(item: &impl Summary) { |
impl Summary ,意思是实现了Summary特征的 item参数
特征约束
虽然impl Trait这种语法非常好理解,但它实际上知识一个语法糖
1 | pub fn notify<T: Summary>(item:&T){ |
真正完整书写形式如上所示,形如T:Summary被称为特征约束
在复杂的场景,特征约束可以让我们拥有更大的灵活性和语法表现能力,例如一个函数接受两个 impl Summary 的参数:
1 | pub fn notify(item1: &impl Summary, item2: &impl Summary) {} |
如果函数两个参数是不同的类型,那么上面的方法很好,只要这两个类型都实现了 Summary 特征即可。但是如果我们想要强制函数的两个参数是同一类型呢?上面的语法就无法做到这种限制,此时我们只能使特征约束来实现:
1 | pub fn notify<T: Summary>(item1: &T, item2: &T) {} |
泛型类型 T 说明了 item1 和 item2 必须拥有同样的类型,同时 T: Summary 说明了 T 必须实现 Summary 特征。
多重约束
除了当约束条件,我们还可以指定多个约束条件,例如除了让参数实现Summary特征外 ,还可以让参数实现Display特征以控制它的格式化输出:
1 | pub fn notify(item: &(impl Summary + Display)) {} |
除了上述的语法糖形式,还能使用特征约束的形式:
1 | pub fn notify<T: Summary + Display>(item: &T) {} |
Where约束
当特征约束变得很多时,函数的签名将变得很复杂:
1 | fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {} |
严格来说,上面的例子还是不够复杂,但是我们还是能对其做一些形式上的改进,通过 where:
1 | fn some_function<T, U>(t: &T, u: &U) -> i32 |
使用特征约束有条件地实现方法或特征
特征约束,可以让我们在指定类型 + 指定特征的条件下去实现方法,例如:
1 | use std::fmt::Display; |
cmp_display 方法,并不是所有的 Pair<T> 结构体对象都可以拥有,只有 T 同时实现了 Display + PartialOrd 的 Pair<T> 才可以拥有此方法。 该函数可读性会更好,因为泛型参数、参数、返回值都在一起,可以快速的阅读,同时每个泛型参数的特征也在新的代码行中通过特征约束进行了约束。
也可以有条件地实现特征,例如,标准库为任何实现了 Display 特征的类型实现了 ToString 特征:
1 | impl<T: Display> ToString for T { |
我们可以对任何实现了 Display 特征的类型调用由 ToString 定义的 to_string 方法。例如,可以将整型转换为对应的 String 值,因为整型实现了 Display:
1 | let s = 3.to_string(); |
函数返回中的impl Trait
可以通过impl Trait来说明一个函数返回了一个类型,该类型实现了某个特征:
1 | fn returns_summarizable() -> impl Summary { |
因为 Weibo 实现了 Summary,因此这里可以用它来作为返回值。要注意的是,虽然我们知道这里是一个 Weibo 类型,但是对于 returns_summarizable 的调用者而言,他只知道返回了一个实现了 Summary 特征的对象,但是并不知道返回了一个 Weibo 类型。
这种 impl Trait 形式的返回值,在一种场景下非常非常有用,那就是返回的真实类型非常复杂,你不知道该怎么声明时(毕竟 Rust 要求你必须标出所有的类型),此时就可以用 impl Trait 的方式简单返回。例如,闭包和迭代器就是很复杂,只有编译器才知道那玩意的真实类型,如果让你写出来它们的具体类型,估计内心有一万只草泥马奔腾,好在你可以用 impl Iterator 来告诉调用者,返回了一个迭代器,因为所有迭代器都会实现 Iterator 特征。
但是这种返回值方式有一个很大的限制:只能有一更具体的类型,例如
1 | fn returns_summarizable(switch: bool) -> impl Summary { |
以上的代码就无法通过编译,因为它返回了两个不同的类型 Post 和 Weibo。
1 | `if` and `else` have incompatible types |
报错提示我们 if 和 else 返回了不同的类型。如果想要实现返回不同的类型,需要使用下一章节中的特征对象。
通过derive派生特征
形如 #[derive(Debug)] 的代码已经出现了很多次,这种是一种特征派生语法,被 derive 标记的对象会自动实现对应的默认特征代码,继承相应的功能。
例如 Debug 特征,它有一套自动实现的默认代码,当你给一个结构体标记后,就可以使用 println!("{:?}", s) 的形式打印该结构体的对象。
再如 Copy 特征,它也有一套自动实现的默认代码,当标记到一个类型上时,可以让这个类型自动实现 Copy 特征,进而可以调用 copy 方法,进行自我复制。
总之,derive 派生出来的是 Rust 默认给我们提供的特征,在开发过程中极大的简化了自己手动实现相应特征的需求,当然,如果你有特殊的需求,还可以自己手动重载该实现。
详细的 derive 列表参见附录-派生特征。
调用方法需要引入特征
在一些场景中,使用as关键字做类型转换会有比较大的限制,因为你想要在类型转换上拥有完全的控制,例如处理转换错误,那么你将需要TryInto:
1 | use std::convert::TryInto; |
上面代码中引入了 std::convert::TryInto 特征,但是却没有使用它,可能有些同学会为此困惑,主要原因在于如果你要使用一个特征的方法,那么你需要将该特征引入当前的作用域中,我们在上面用到了 try_into 方法,因此需要引入对应的特征。
但是 Rust 又提供了一个非常便利的办法,即把最常用的标准库中的特征通过 std::prelude 模块提前引入到当前作用域中,其中包括了 std::convert::TryInto,你可以尝试删除第一行的代码 use ...,看看是否会报错。
特征对象
1 | fn returns_summarizable(switch: bool) -> impl Summary { |
Post和Weibo都实现了Summary特征,因此上面的函数识图通过返回impl Summary来返回这两个类型,但是编译器报错了,原因是impl Trait的返回值类型并不支持多种不同类型返回,那我们向返回多种类型,该怎么办
再来考虑一个问题:现在在做一款游戏,需要将多个对象渲染在屏幕上,这些对象属于不同的类型,存储在列表中,渲染的时候,需要循环该列表并顺序渲染每个对象,在 Rust 中该怎么实现?
聪明的同学可能已经能想到一个办法,利用枚举:
1 |
|
Bingo,这个确实是一个办法,但是问题来了,如果你的对象集合并不能事先明确地知道呢?或者别人想要实现一个 UI 组件呢?此时枚举中的类型是有些缺少的,是不是还要修改你的代码增加一个枚举成员?
总之,在编写这个 UI 库时,我们无法知道所有的 UI 对象类型,只知道的是:
- UI 对象的类型不同
- 需要一个统一的类型来处理这些对象,无论是作为函数参数还是作为列表中的一员
- 需要对每一个对象调用
draw方法
在拥有继承的语言中,可以定义一个名为 Component 的类,该类上有一个 draw 方法。其他的类比如 Button、Image 和 SelectBox 会从 Component 派生并因此继承 draw 方法。它们各自都可以覆盖 draw 方法来定义自己的行为,但是框架会把所有这些类型当作是 Component 的实例,并在其上调用 draw。不过 Rust 并没有继承,我们得另寻出路。
特征对象定义
在介绍特征对象之前,先来为之前的UI组件定义一个特征:
1 | pub trait Draw { |
只要组件实现了Draw特征,就可以调用Draw方法来进行渲染。假设有一个Button和SelectBox组件实现了Draw特征
1 | pub struct Button { |
此时,还需要一个动态数组来存储这些UI对象:
1 | pub struct Screen { |
注意到上面的?,它的意思是我们应该填入什么类型,在之前的内容中,我们找不到那个类型可以填入,但是因为Button和SelectBox都实现了Draw特征,那我们就可以把Draw特征的对象作为类型,填入数组中
特征对象指向实现了Draw特征的类型的实力,也就是指向了Button和SelectBox的实例,这种映射关系是存储在一张表中,可以在运行时通过特征对象找到具体调用的类型方法
可以通过&引用或者Box<T>智能指针来创建特征对象
Box<T>在后面会详细讲解,大家现在把它当成一个引用即可,只不过它包裹的值会被强制分配在堆上。
dyn关键字用于表示动态分发(dynamic dispatch)的特征对象。它允许你在运行时确定调用哪个方法,而不是在编译时确定。这是 Rust 中实现多态的一种方式,特别是在处理具有共同接口(特征)的不同类型时。
1 | trait Draw { |
上面代码,有几个非常重要的点:
draw1函数的参数是Box<dyn Draw>形式的特征对象,该特征对象是通过Box::new(x)的方式创建的draw2函数的参数是&dyn Draw形式的特征对象,该特征对象是通过&x的方式创建的dyn关键字只用在特征对象的类型声明上,在创建时无需使用dyn
因此,可以使用特征对象来代表泛型或具体的类型。
继续来完善之前的 UI 组件代码,首先来实现 Screen:
1 | pub struct Screen { |
其中存储了一个动态数组,里面的元素类型是Draw特征对象:Box<dyn Draw>,任何实现了Draw特征的类型都可以存放其中
我们再来为Screen定义run方法,用于将列表中的UI组件渲染到屏幕上
1 | impl Screen { |
至此,我们就完成了之前的目标:在列表中存储多种不同类型的实力,然后将他们使用同一个方法逐一渲染到屏幕上
我们再来看看,如果通过泛型实现,会如何:
1 | pub struct Screen<T: Draw> { |
上面的Screen的列表中,存储了类型为T的元素,然后再Screen中使用特征约束让T实现了 Draw 特征,进而可以调用 draw 方法。
但是这种写法限制了 Screen 实例的 Vec<T> 中的每个元素必须是 Button 类型或者全是 SelectBox 类型。如果只需要同质(相同类型)集合,更倾向于采用泛型+特征约束这种写法,因其实现更清晰,且性能更好(特征对象,需要在运行时从 vtable 动态查找需要调用的方法)。
现在来运行渲染下咱们精心设计的 UI 组件列表:
1 | fn main() { |
上面使用 Box::new(T) 的方式来创建了两个 Box<dyn Draw> 特征对象,如果以后还需要增加一个 UI 组件,那么让该组件实现 Draw 特征,则可以很轻松的将其渲染在屏幕上,甚至用户可以引入我们的库作为三方库,然后在自己的库中为自己的类型实现 Draw 特征,然后进行渲染。
在动态类型语言中,有一个很重要的概念:鸭子类型(duck typing),简单来说,就是只关心值长啥样,而不关心它实际是什么。当一个东西走起来像鸭子,叫起来像鸭子,那么它就是一只鸭子,就算它实际上是一个奥特曼,也不重要,我们就当它是鸭子。
在上例中,Screen 在 run 的时候,我们并不需要知道各个组件的具体类型是什么。它也不检查组件到底是 Button 还是 SelectBox 的实例,只要它实现了 Draw 特征,就能通过 Box::new 包装成 Box<dyn Draw> 特征对象,然后被渲染在屏幕上。
使用特征对象和 Rust 类型系统来进行类似鸭子类型操作的优势是,无需在运行时检查一个值是否实现了特定方法或者担心在调用时因为值没有实现方法而产生错误。如果值没有实现特征对象所需的特征, 那么 Rust 根本就不会编译这些代码:
1 | fn main() { |
因为 String 类型没有实现 Draw 特征,编译器直接就会报错,不会让上述代码运行。如果想要 String 类型被渲染在屏幕上,那么只需要为其实现 Draw 特征即可,非常容易。
注意 dyn 不能单独作为特征对象的定义,例如下面的代码编译器会报错,原因是特征对象可以是任意实现了某个特征的类型,编译器在编译期不知道该类型的大小,不同的类型大小是不同的。
而 &dyn 和 Box<dyn> 在编译期都是已知大小,所以可以用作特征对象的定义。
1 | fn draw2(x: dyn Draw) { |
特征对象的动态分发
我们之前学过泛型,是在编译期完成处理的:编译期会为每一个泛型参数对应的具体类型生成一份代码,这种方式是静态分发,由于是在编译期完成的,对于运行期性能完全没有影响
与静态分发相对应的是动态分发,在这种情况下,直到运行时,才能确定需要调用什么方法,之前代码的dyn正是在强调这一”动态特点”
当使用特征对象时,Rust必须使用动态分发。编译器无法知晓所有可能用于特征对象代码的类型,所以它也不知道应该调用哪个类型的哪个方法实现。为此,Rust 在运行时使用特征对象中的指针来知晓需要调用哪个方法。动态分发也阻止编译器有选择的内联方法代码,这会相应的禁用一些优化。
下面这张图很好的解释了静态分发 Box<T> 和动态分发 Box<dyn Trait> 的区别:

结合上文的内容和这张图可以了解:
- 特征对象大小不固定:这是因为,对于特征
Draw,类型Button可以实现特征Draw,类型SelectBox也可以实现特征Draw,因此特征没有固定大小 - 几乎总是使用特征对象的引用方式,如&dyn Draw、Box<dyn Draw>
- 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(
ptr和vptr),因此占用两个指针大小 - 一个指针
ptr指向实现了特征Draw的具体类型的实例,也就是当作特征Draw来用的类型的实例,比如类型Button的实例、类型SelectBox的实例 - 另一个指针
vptr指向一个虚表vtable,vtable中保存了类型Button或类型SelectBox的实例对于可以调用的实现于特征Draw的方法。当调用方法时,直接从vtable中找到方法并调用。之所以要使用一个vtable来保存各实例的方法,是因为实现了特征Draw的类型有多种,这些类型拥有的方法各不相同,当将这些类型的实例都当作特征Draw来使用时(此时,它们全都看作是特征Draw类型的实例),有必要区分这些实例各自有哪些方法可调用
- 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(
简而言之,当类型 Button 实现了特征 Draw 时,类型 Button 的实例对象 btn 可以当作特征 Draw 的特征对象类型来使用,btn 中保存了作为特征对象的数据指针(指向类型 Button 的实例数据)和行为指针(指向 vtable)。
一定要注意,此时的 btn 是 Draw 的特征对象的实例,而不再是具体类型 Button 的实例,而且 btn 的 vtable 只包含了实现自特征 Draw 的那些方法(比如 draw),因此 btn 只能调用实现于特征 Draw 的 draw 方法,而不能调用类型 Button 本身实现的方法和类型 Button 实现于其他特征的方法。也就是说,btn 是哪个特征对象的实例,它的 vtable 中就包含了该特征的方法。
Self 与 self
在 Rust 中,有两个self,一个指代当前的实例对象,一个指代特征或者方法类型的别名:
1 | trait Draw { |
上述代码中,self指代的就是当前的实例对象,也就是 button.draw() 中的 button 实例,Self 则指代的是 Button 类型。
当理解了 self 与 Self 的区别后,我们再来看看何为对象安全。
特征对象的限制
不是所有特征都能拥有特征对象,只有对象安全的特征才行。当一个特征的所有方法都有如下属性时,它的对象才是安全的:
- 方法的返回类型不能是
Self - 方法没有任何泛型参数
对象安全对于特征对象是必须的,因为一旦有了特征对象,就不再需要知道实现该特征的具体类型是什么了。如果特征方法返回了具体的 Self 类型,但是特征对象忘记了其真正的类型,那这个 Self 就非常尴尬,因为没人知道它是谁了。但是对于泛型类型参数来说,当使用特征时其会放入具体的类型参数:此具体类型变成了实现该特征的类型的一部分。而当使用特征对象时其具体类型被抹去了,故而无从得知放入泛型参数类型到底是什么。
标准库中的 Clone 特征就不符合对象安全的要求:
1 | pub trait Clone { |
因为它的其中一个方法,返回了 Self 类型,因此它是对象不安全的。
String 类型实现了 Clone 特征, String 实例上调用 clone 方法时会得到一个 String 实例。类似的,当调用 Vec<T> 实例的 clone 方法会得到一个 Vec<T> 实例。clone 的签名需要知道什么类型会代替 Self,因为这是它的返回值。
如果违反了对象安全的规则,编译器会提示你。例如,如果尝试使用之前的 Screen 结构体来存放实现了 Clone 特征的类型:
1 | pub struct Screen { |
将会得到如下错误:
1 | error[E0038]: the trait `std::clone::Clone` cannot be made into an object |
这意味着不能以这种方式使用此特征作为特征对象。
深入了解特征
关联类型
关联类型是在特征定义的语句块中声明一个自定义类型,这样就可以在特征的方法签名中使用该类型:
1 | pub trait pub trait Iterator { |
上面是标准库中迭代器特征Iterator,它有一个Item关联类型,用于替代遍历的值的类型
同时,next也返回了一个Item类型,不过使用了Option枚举进行了包裹,假如迭代器中的值是i32类型,那么调用next方法就将获取到一个Option<i32>的值
Self用来指代当前调用者的具体类型,那么Self::Item就用来指代该类型实现中定义的Item类型:
1 | impl Iterator for Counter { |
在上述代码中,我们为Counter类型实现了Iterator特征,变量c是特征Iterator的实力,也是next方法的调用者。结合之前的黑体内容可以得到:对于next方法而言,Self是调用者c的具体类型 Counter,而 Self::Item 是 Counter 中定义的 Item 类型: u32。