[网鼎杯 2020 青龙组]you_raise_me_up(大步小步算法)
首先,我们审计题目,可以发现题目中给予了我们m、c和n的值,其中n=2**512,m则是在(2,m)之间的值,c是m^flag = c mod n
可以看出,这是一道求指标的题目,我们可以通过以下方法进行计算,已知的条件为:
2^e = c1 mod n 在这其中,除了e其余条件我们都已知,在这里,我们需要使用离散对数求解的思路:
Shanks’s Babystep-Giantstep Algorithm算法:
1、n=[ √n ]+12、构造两个列表
list1=[1,g,g^2,g^3,……,g^n]
list2=[h,hg^(-n),hg^(-2n),……,hg^(-n**2)]
3、在两个列表中,找到两个相同的数 g^i=hg^(-jn)
=>g^(i+jn)=h mod n
4、我们所求的e=i+jn
python库应用:python(sympy库) x=sympy.discrete_log(n,a,g)
exp
1 | m = 391190709124527428959489662565274039318305952172936859403855079581402770986890308469084735451207885386318986881041563704825943945069343345307381099559075 |
救世捷径(dijstra算法)
这道题感觉跟acm的寻找最短路径一样.
txt文件中每行的前两个数字作为无向图的顶点,第三个数字是两顶点之间的距离,最后的字符串是两顶点之间的内容,将起点到终点最短路径经过的边上的内容组合起来便是flag。
单源点最短路径算法:dijstra算法。
一些想到哪是哪的tips写在这里咯:
1.一些前期的初始化和数据处理
1)初始化各点之间的距离为“无穷远”(在程序中用一个比较大的数代替这个无穷远的概念),一般可以直观地想出用27*27的二维数组存这些距离值(Python中是用list套list作为过去高级语言中二维数组的那种存在……而且要注意要初始化把list里面都放上东西才行!),之后我们就操作索引是1-26的那些元素,浪费掉位置0处的空间,但可以恰好对应顶点1-26,清晰明了~
2)按行读取题目txt文件中的内容,用的是readlines(),得到的数据形式是每行作为一个元素组成的list。然后用strip()去掉行尾的换行符’\n’,再用split(’ ‘)将每行内容按空格分割组成新的list,方便后面在程序中的调用。
3)因为在2)步中已经分割出了每行的元素,就可以用2)步中的数据去初始化1)步中27*27的list中的数据,把已知的那些两点之间的距离放入即可,具体写法见程序代码。
2.实现dijstra算法的函数
1)初始化一个长度是27,元素全是0xffff(代表距离很远)的list,用于记录当前顶点(索引与顶点序号一致是1-26)对于顶点1的最短距离。
2)初始化一个长度为27,元素全是0的list,元素值用于记录当前顶点(索引与顶点序号一致是1-26)是否已经找到了距离顶点1的最短路径,确定了最短路径就置该顶点序号对应索引值的元素为1。后面将这里元素值是1的顶点称为“已经确定的集合”。每次更新完各顶点到顶点1的距离后,找到最短的一个,将该顶点位置元素置1,该顶点就不再参与后续的遍历。
3)初始化一个长度为27,元素全是1的list,用于记录当前顶点到顶点1的最短路径的前驱顶点,用于最后回溯路径。
过程:
首先找到和顶点1直连的顶点,找到这些顶点中距离顶点1最短的一个顶点,将该顶点加入“已经确定的集合“,遍历该顶点的邻接顶点,更新顶点1到各个邻接顶点的最短距离。再找到现在与顶点1距离最短的顶点(在”已经确定的集合“中的顶点就不再遍历),再去遍历该顶点的邻接顶点,更新顶点1到这些邻接顶点的最短距离,从中找到距离最短的顶点加入“已经确定的集合”,再遍历该顶点的邻接顶点,更新这些顶点与顶点1的最短距离,找到与顶点1距离最短的顶点……以此循环直至所有顶点都加入“确定的集合”。
核心思想:
每次循环都找到当前距离顶点1最近的一个顶点,判断路径中经过该顶点后再到达与其邻接的其他顶点的距离,是否比之前存储的这些顶点到顶点1的距离更短,如果更短就更新对应顶点到顶点1的最短距离,更新完后再找到与顶点1距离最短的顶点重复上述操作。
1 | graph=[] |
[GKCTF 2021]Random(梅森算法)
1 | import random |
通过阅读代码,我们知道是求生成104组随机数后的卜随机数
通过算法出的随机数是伪随机数,这里用到的随机数生成函数式random.getrandbits(k)
random.getrandbits(k)
返回具有 k 个随机比特位的非负 Python 整数。 此方法随 MersenneTwister 生成器一起提供,其他一些生成器也可能将其作为 API 的可选部分提供。 在可能的情况下,getrandbits() 会启用 randrange() 来处理任意大的区间。在 3.9 版更改: 此方法现在接受零作为 k 的值。
所以这题考的其实是梅森算法,Mersenne Twister是为了解决过去伪随机生成器PRNG产生的伪随机数质量不高而生成的(传送门:梅森旋转算法)。我们了解MT19937能做生成在1<=k<=623个均匀分布的32位随机数。而真巧我们已经有624((104+104*64/32+104*96/32)=624)个生成的随机数了,也就是说,根据已有的随机数,我们完全可以推出下面会生成的随机数
我们需要用到rendcrack库
先了解一下rendcrack
randcrack
工作原理
该生成器基于M e r s e n n e T w i s t e r MersenneTwisterMersenneTwister(梅森算法),能够生成具有优异统计特性的数字(与真正的随机数无法区分)。但是,此生成器的设计目的不是加密安全的。您不应在关键应用程序中用作加密方案的PRNG。
您可以[在维基百科上]了解有关此生成器的更多信息(https://en.wikipedia.org/wiki/Mersenne_Twister).
这个饼干的工作原理如下。
它从生成器获得前624个32位数字,并获得Mersenne Twister矩阵的最可能状态,即内部状态。从这一点来看,发电机应该与裂解器同步。
如何使用
将生成器生成的32位整数准确地输入cracker非常重要,因为它们无论如何都会生成,但如果您不请求它们,则会删除它们。 同样,您必须在出现新种子之后,或者在生成624 ∗ 32 位之后,准确地为破解程序馈电,因为每个624 ∗ 32 位数字生成器都会改变其状态,并且破解程序设计为从某个状态开始馈电。
1 | from hashlib import md5 |
脚本源于:
代码就很容易读懂了,先将我们有的随机数排列到一个列表ll中,然后挨个用RandCrack.submit()提交,最后用RandCrack.predict_getrandbits()预测下一个32位随机数,然后md5一下输出就好了
[SUCTF2019]MT(梅森算法)
考点是MT19937,也就是梅森旋转算法
1 | from Crypto.Random import random |
加密原理很简单,就是通过 convert() 函数获取随机数将 flag 加密。考的题型是 逆向 extract_number函数
解题EXP:
1 | #python2 |
第二种解法是基于出题人的算法,使得明文通过不断的加密最后还是明文。
1 | #python2 |
[De1CTF2019]xorz(重复密钥异或用汉明距离)
1 | from itertools import * |
cycle函数
cycle() 函数是 Python 标准库 itertools 中的一个函数,可以在一个可迭代对象(例如列表、元组或字符串)中无限循环遍历元素。
zfill函数
返回指定长度的字符串,原字符串右对齐,前面填充0。
我们来审计代码,代码使用了p、ki、si进行了异或,未知部分有两个,flag和plain,最后输出结果是16进制的密文,salt和key都是循环使用的
salt是已知的,因此先把salt层去掉
1 | from itertools import * |
1 | no_salt =1e5d4c055104471c6f234f5501555b5a014e5d001c2a54470555064c443e235b4c0e590356542a130a4242335a47551a590a136f1d5d4d440b0956773613180b5f184015210e4f541c075a47064e5f001e2a4f711844430c473e2413011a100556153d1e4f45061441151901470a196f035b0c4443185b322e130806431d5a072a46385901555c5b550a541c1a2600564d5f054c453e32444c0a434d43182a0b1c540a55415a550a5e1b0f613a5c1f10021e56773a5a0206100852063c4a18581a1d15411d17111b052113460850104c472239564c0755015a13271e0a55553b5a47551a54010e2a06130b5506005a393013180c100f52072a4a1b5e1b165d50064e411d0521111f235f114c47362447094f10035c066f19025402191915110b4206182a544702100109133e394505175509671b6f0b01484e06505b061b50034a2911521e44431b5a233f13180b5508131523050154403740415503484f0c2602564d470a18407b775d031110004a54290319544e06505b060b424f092e1a770443101952333213030d554d551b2006064206555d50141c454f0c3d1b5e4d43061e453e39544c17580856581802001102105443101d111a043c03521455074c473f3213000a5b085d113c194f5e08555415180f5f433e270d131d420c1957773f560d11440d40543c060e470b55545b114e470e193c155f4d47110947343f13180c100f565a000403484e184c15050250081f2a54470545104c5536251325435302461a3b4a02484e12545c1b4265070b3b5440055543185b36231301025b084054220f4f42071b1554020f430b196f19564d4002055d79 |
去掉salt层后,就只剩下plain和key了,key就是我们要求的flag,这里我们注意到key的位数小于38位,所以使用key来循环异或加密的,对于利用重复密钥异或的情况,我们有现成的脚本Break repeating-key XOR,原理为汉明距离hamming_distance
例子
- “karolin” and “kathrin” is 3.
- “karolin” and “kerstin” is 3.
- 1011101 and 1001001 is 2.
- 2173896 and 2233796 is 3.
汉明距离(Hamming Distance) 是衡量两个字符串(或两个二进制数)之间的差异的度量。它表示的是两个字符串(或二进制数)中相同位置上不同字符的个数。简而言之,它就是计算两个字符串中对应字符不同的位置的数量。
或者
hamming_distance:在信息论中表示两个等长字符串在对应位置上不同字符的数目 以d(x, y)表示字符串x和y之间的汉明距离 简单来说 汉明距离度量了通过替换字符的方式将字符串x变成y所需要的最小的替换次数
1 | # coding:utf-8 |

参考
https://www.jianshu.com/p/ecd767d9af0d
https://xz.aliyun.com/t/3256#toc-22
https://cypher.codes/writing/cryptopals-challenge-set-1
https://cryptopals.com/sets/1/challenges/6
[羊城杯 2020]GMC(二次剩余和勒让德符号)
[De1CTF2019]Babylfsr(B-M算法)
参考:ctfwiki
[UTCTF2020]Curveball(Shamir秘密共享算法)
Shamir秘密共享算法基本原理


1 | (C81E728D9D4C2F636F067F89CC14862C, 31E96A93BF1A7CE1872A3CCDA6E07F86) |
题目中的三组数据为md5加密后的数据,md5解密得到
1 | (2,5398141) |
所以用sage在有限域上解密 exp.sage
1 | x_0,y_0 = (2,5398141) |
得到
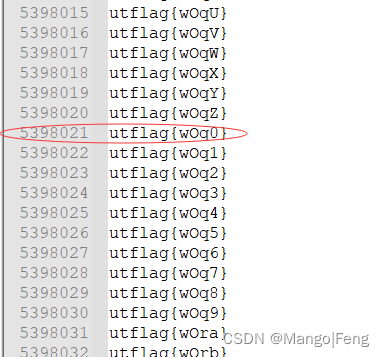
1 | 29*x^2 + 2*x + 5398021 |
但5398021不是flag,那只能是txt行数,我们在5398021看到flag